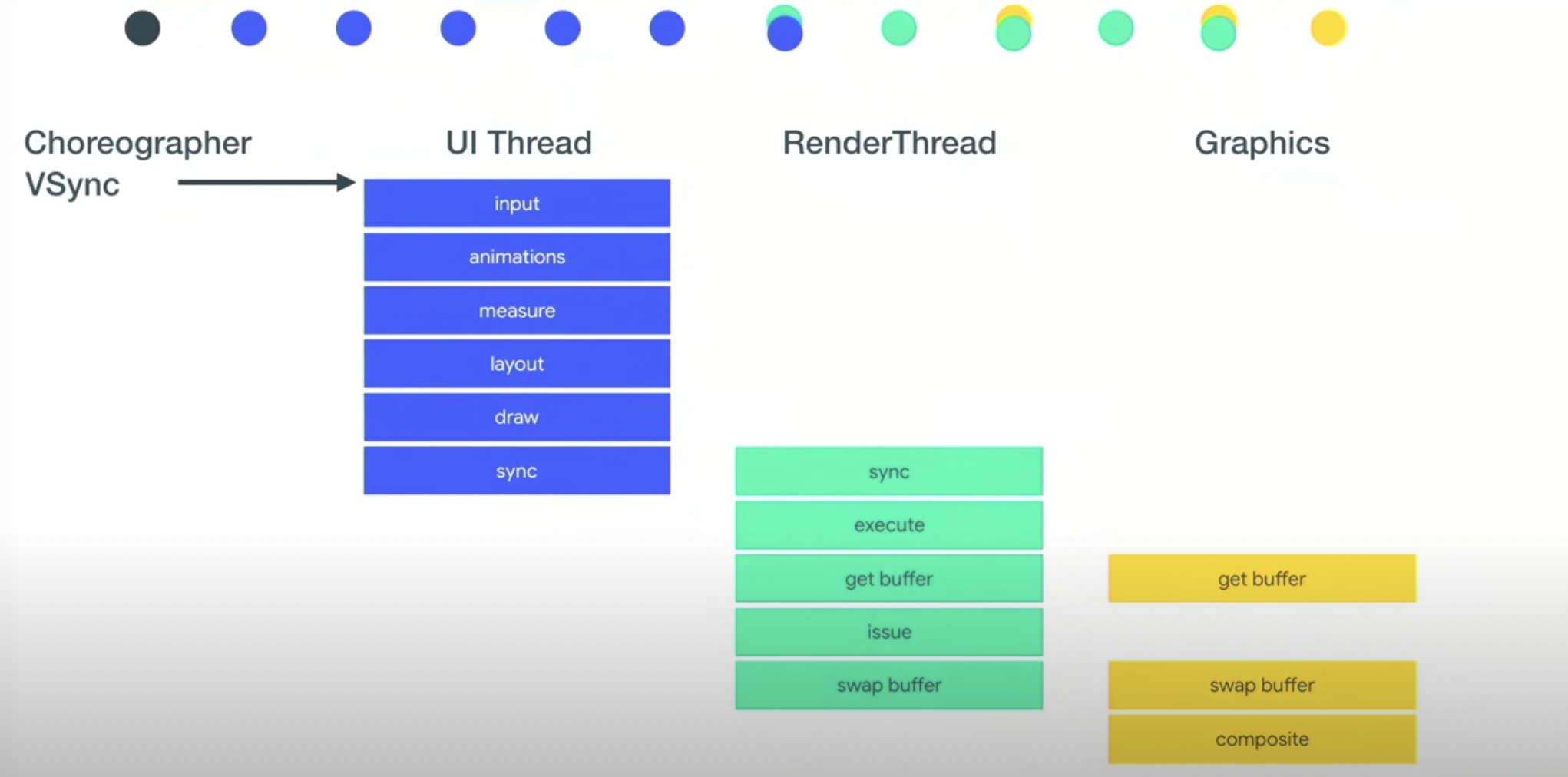
 2018年的流转图。解释一下这个图上的点和下面的条对应关系。
2018年的流转图。解释一下这个图上的点和下面的条对应关系。
当一个用户点击了 RecyclerView 的 item 发生了什么
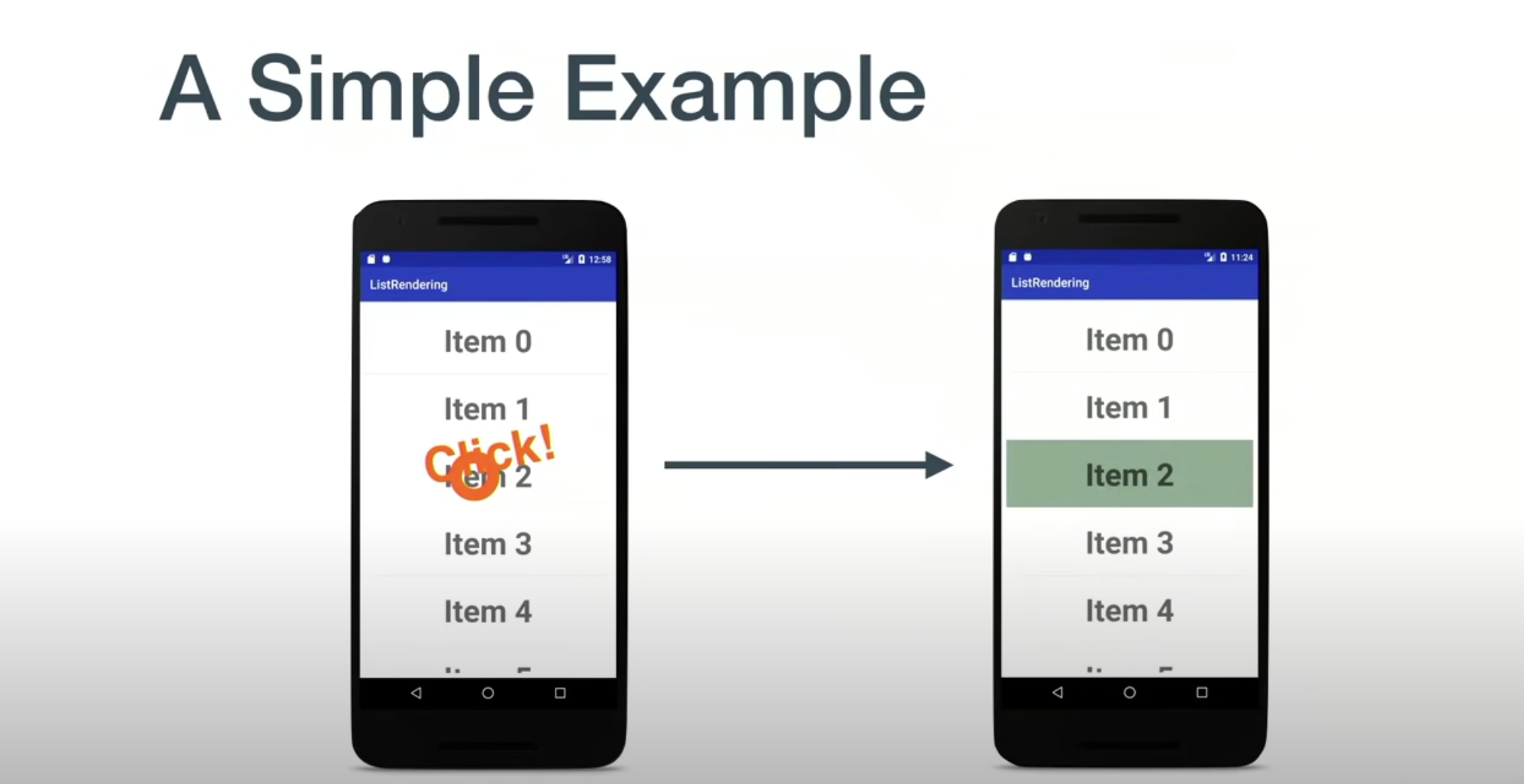 模拟一个简单的点击触发修改屏幕像素的流程。
模拟一个简单的点击触发修改屏幕像素的流程。
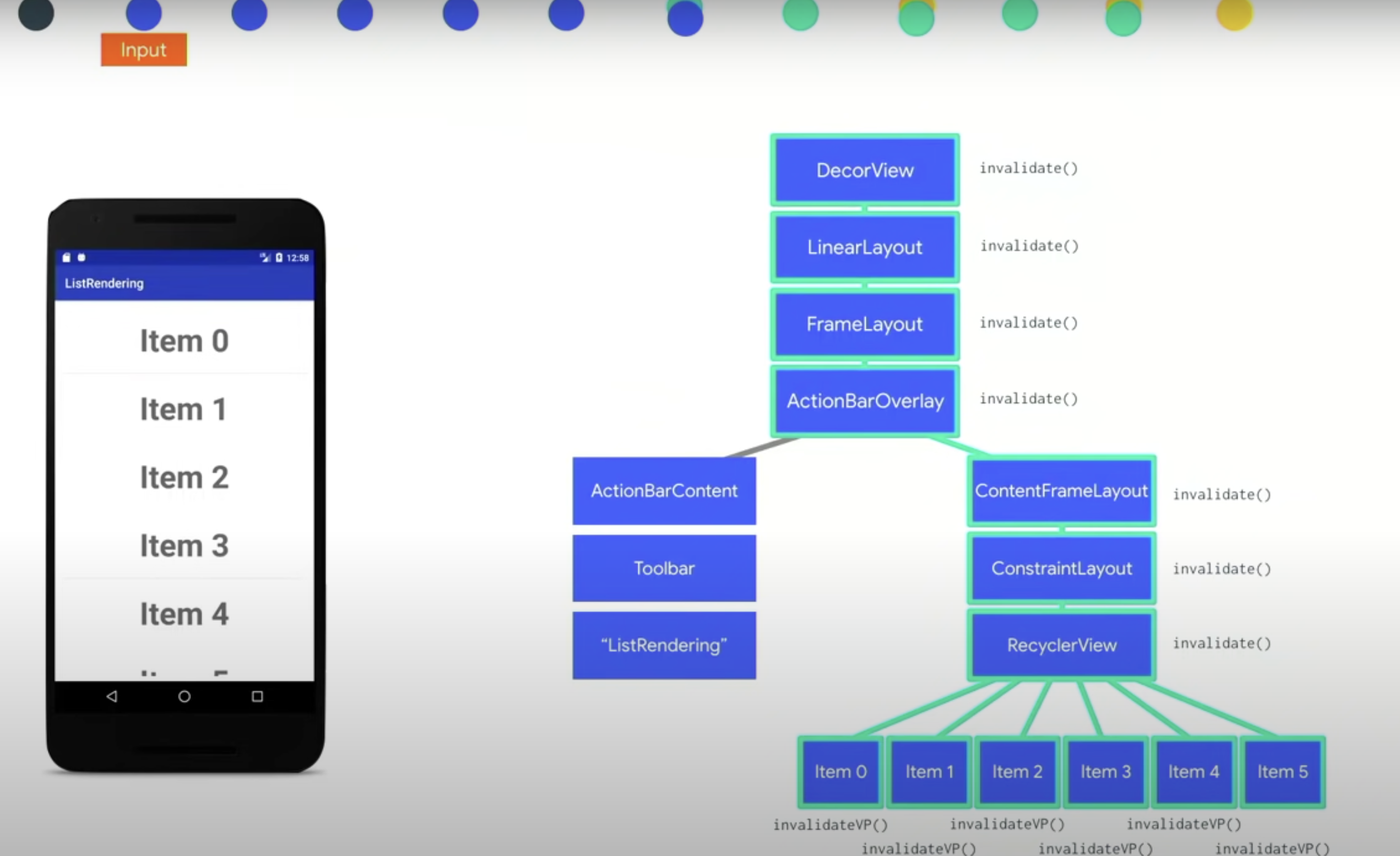
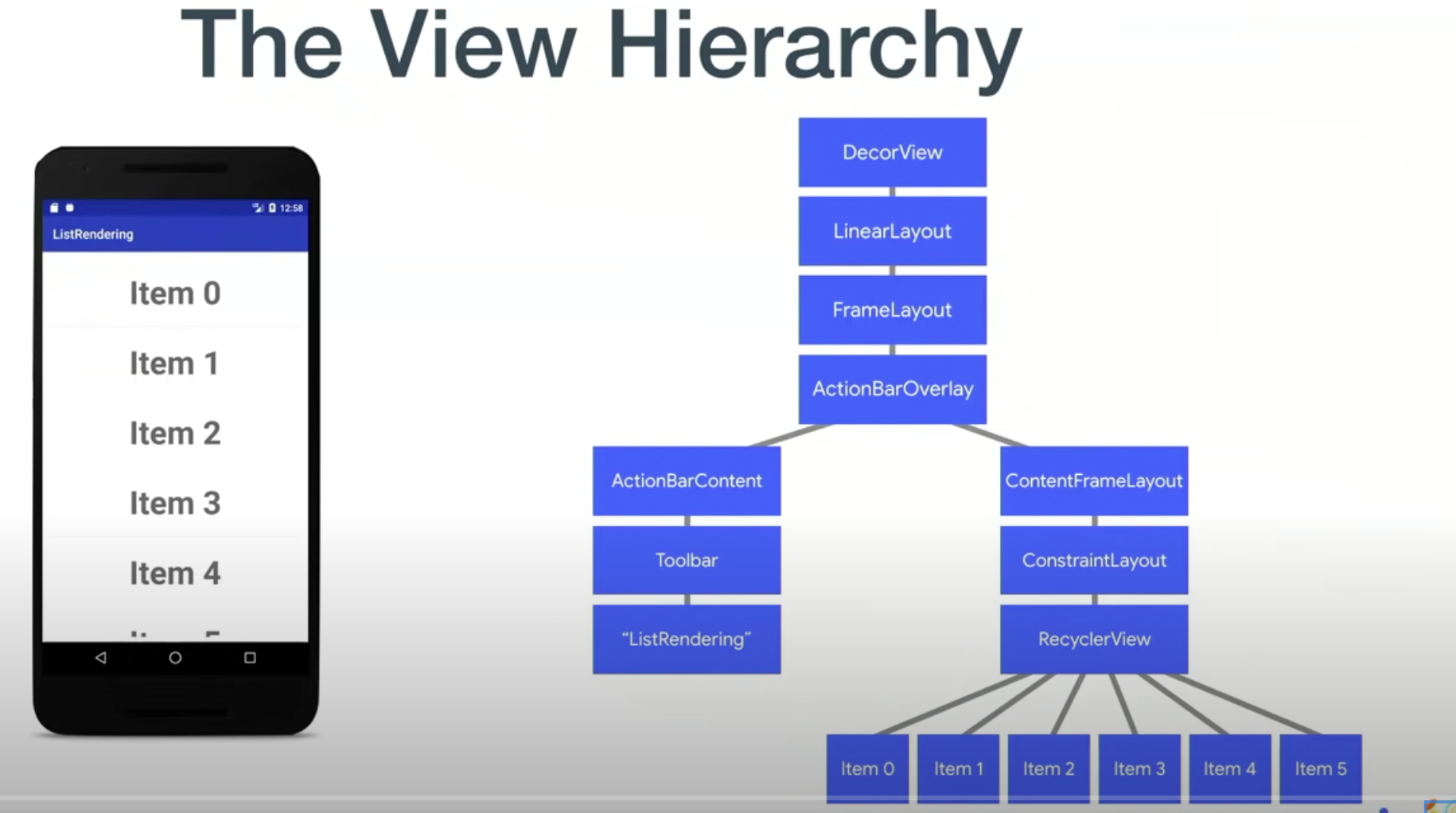 整个 Android 的层次结构
整个 Android 的层次结构
 实际上一般app发生 measure(测量大小) layout(布局位置) draw(绘制内容) 的的区域。这具体的部分是我们当前 app 自己的视图结构(View Hierarchy)。
实际上一般app发生 measure(测量大小) layout(布局位置) draw(绘制内容) 的的区域。这具体的部分是我们当前 app 自己的视图结构(View Hierarchy)。
 也就是这样的 xml 布局。
也就是这样的 xml 布局。
 最终调用到了,framework层的View.java中的 invalidate()
最终调用到了,framework层的View.java中的 invalidate()
 Invalidation 机制本身并不做任何的绘制,而是告诉视图结构(View Hierarchy)需要被绘制了的处理机制。他会从下到上传递失效状态,并在顶层开始调用重新绘制。
Invalidation 机制本身并不做任何的绘制,而是告诉视图结构(View Hierarchy)需要被绘制了的处理机制。他会从下到上传递失效状态,并在顶层开始调用重新绘制。
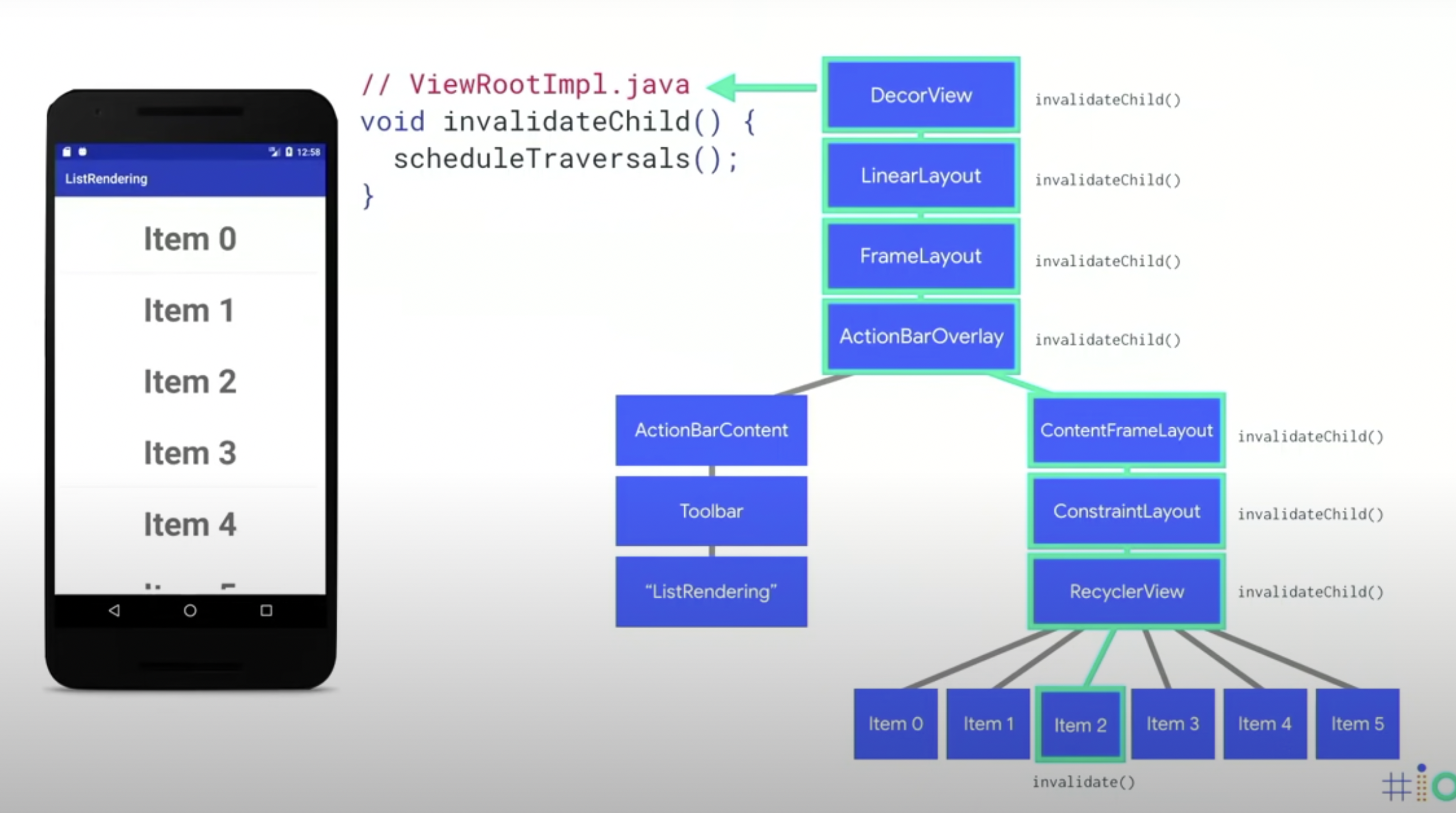 然后会到ViewRootImpl的invalidateChild(),他调用了scheduleTraversals()
然后会到ViewRootImpl的invalidateChild(),他调用了scheduleTraversals()
 执行渲染的所有阶段.也就是 measure layout draw。scheduleTraversals 最后调用 performDraw,最后触发了 draw。这里有个硬件加速的分支优化,硬件加速开启时,会通过 GetDisplayList 来走,否则是传统的 view 渲染逻辑。
执行渲染的所有阶段.也就是 measure layout draw。scheduleTraversals 最后调用 performDraw,最后触发了 draw。这里有个硬件加速的分支优化,硬件加速开启时,会通过 GetDisplayList 来走,否则是传统的 view 渲染逻辑。
 DisplayList 是一个存储了渲染信息的类型结构,所有的 Canvas 中的 drawLine drawBackgroud 等操作都会被存储在 DisplayList,这是一种压缩渲染信息的一种方式。
DisplayList 是一个存储了渲染信息的类型结构,所有的 Canvas 中的 drawLine drawBackgroud 等操作都会被存储在 DisplayList,这是一种压缩渲染信息的一种方式。
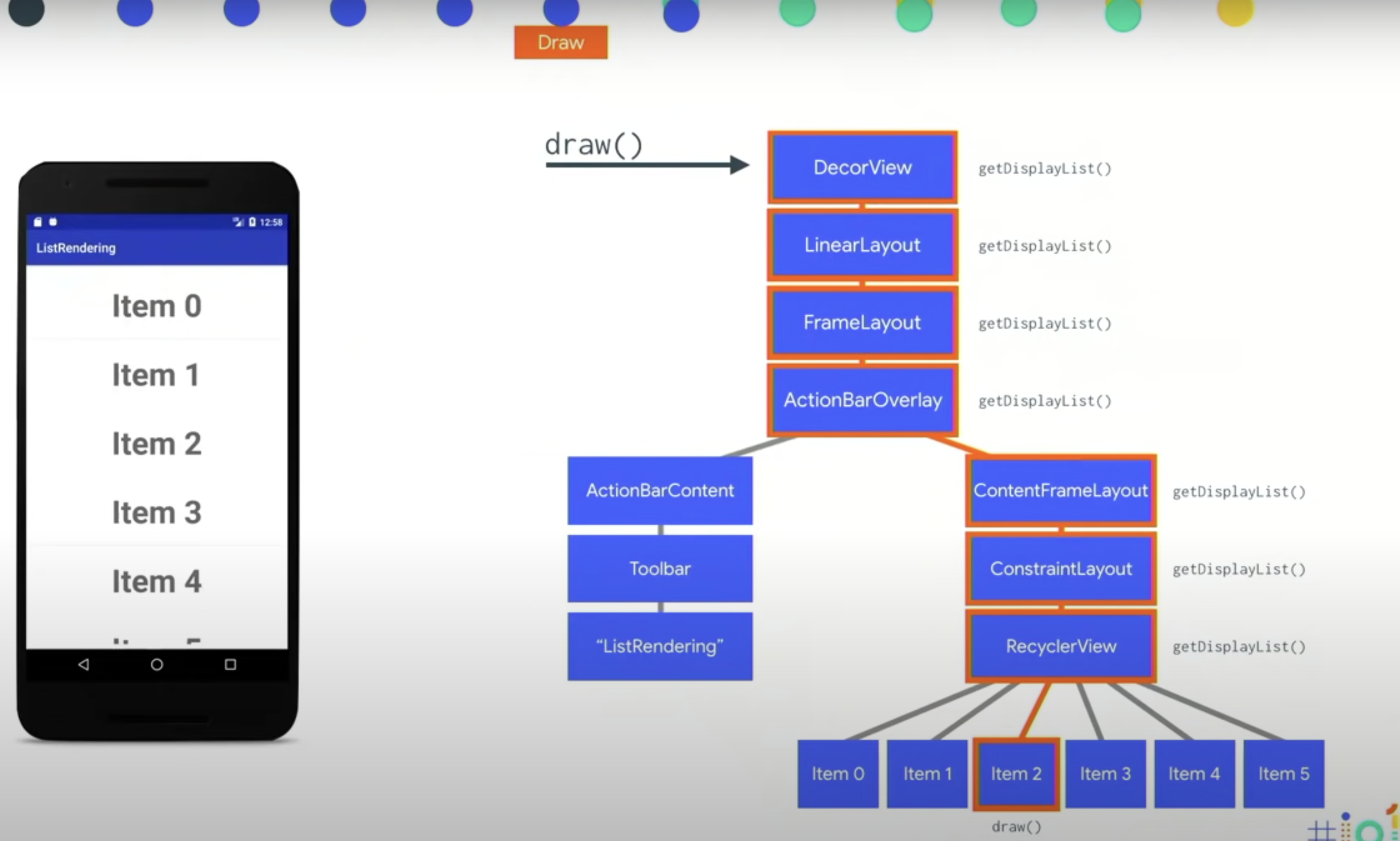 然后回到刚刚说的 GetDisplayList ,视图层次每一层都会调用,然后和之前的进行对比看是否有变更来重新渲染。
然后回到刚刚说的 GetDisplayList ,视图层次每一层都会调用,然后和之前的进行对比看是否有变更来重新渲染。
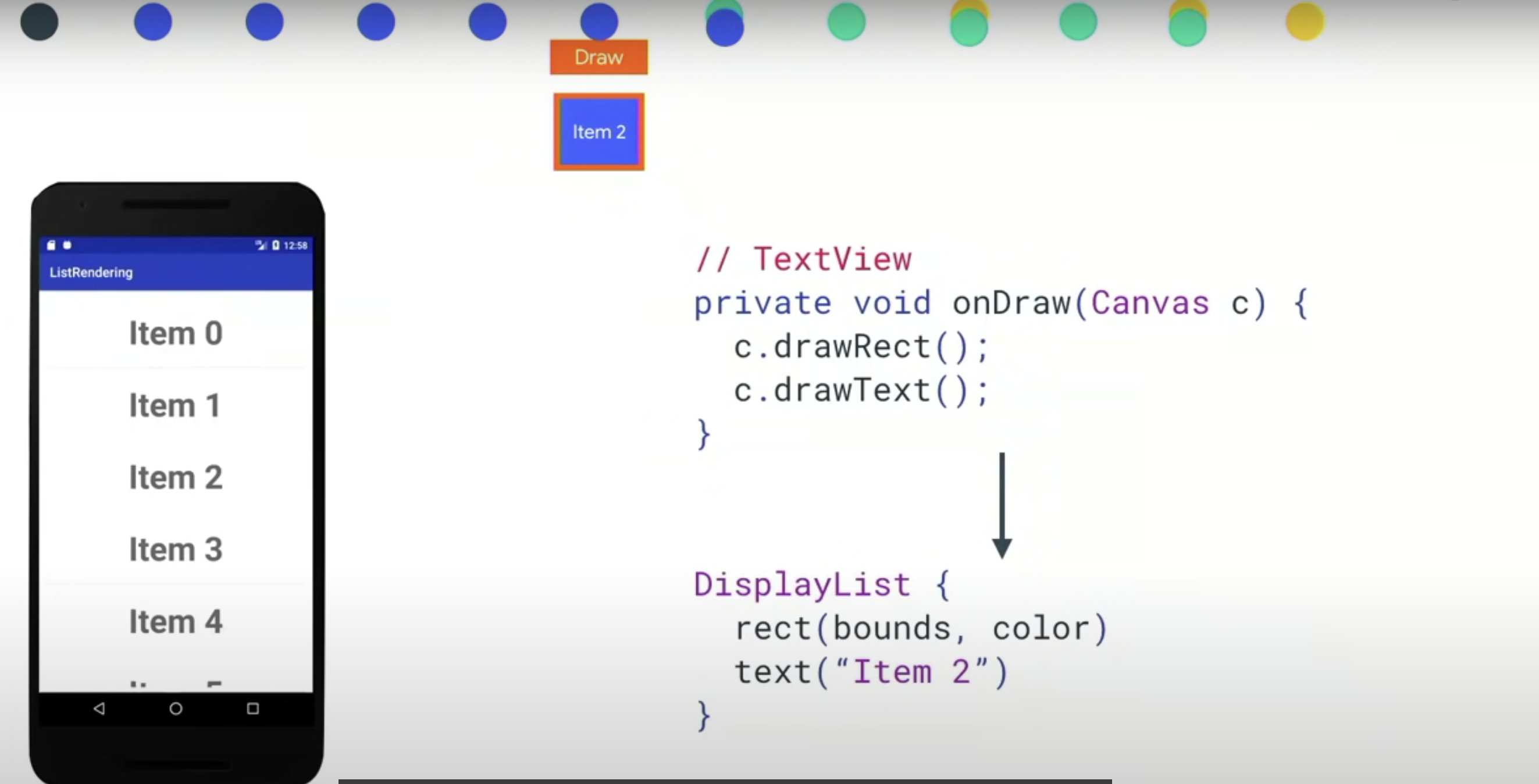 最后在 item2 上发现了变更并且重新生成 DisplayList,最终调用 drawcall。
最后在 item2 上发现了变更并且重新生成 DisplayList,最终调用 drawcall。
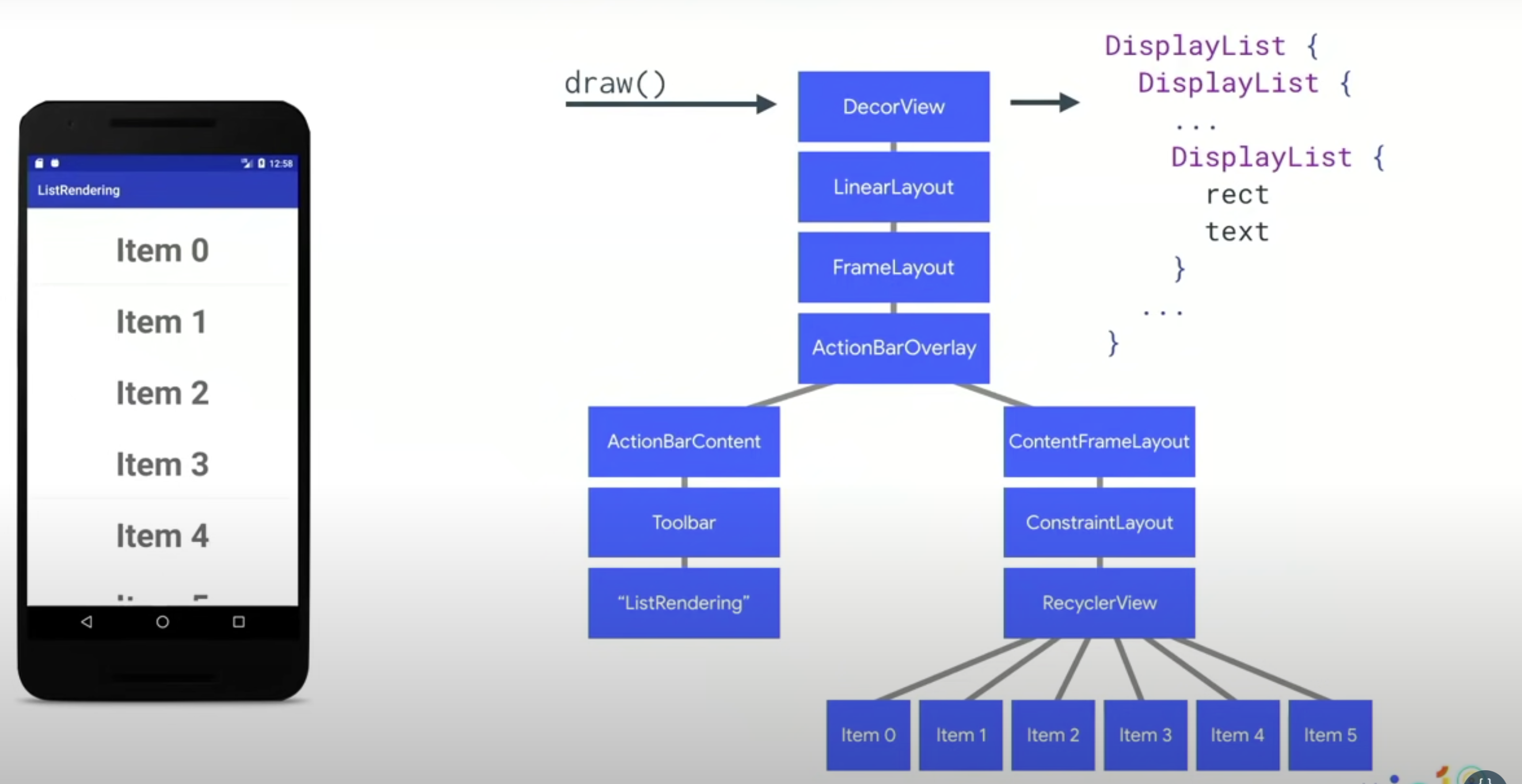 DisplayList的层次和视图层次一样。
DisplayList的层次和视图层次一样。
 到这一步,我们的 Application 这一层所做的事情都做完了,这也是我们在 UI线程 上做的。现在我们要将这些信息给 Sync(同步)到专门被用来和 GPU 打交道的 RenderThread(渲染线程)中。在 JAVA 中生成的信息已经有了,剩下就是在 native 中获取这些信息然后同步给 GPU。
到这一步,我们的 Application 这一层所做的事情都做完了,这也是我们在 UI线程 上做的。现在我们要将这些信息给 Sync(同步)到专门被用来和 GPU 打交道的 RenderThread(渲染线程)中。在 JAVA 中生成的信息已经有了,剩下就是在 native 中获取这些信息然后同步给 GPU。
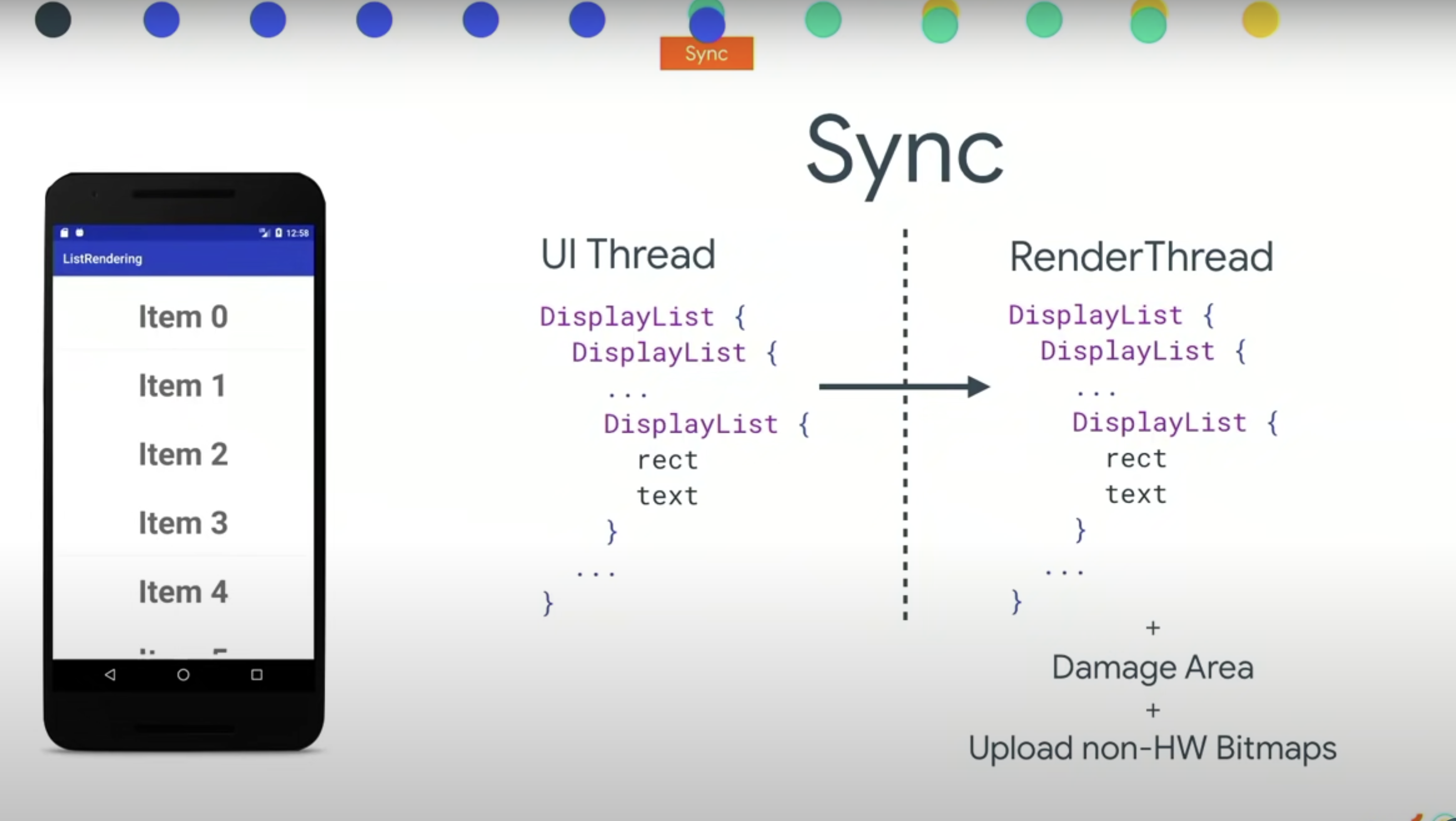 复制到 RenderThread 中的除了 DisplayList ,还有 Damage Area(损坏区域)和 上传非硬件位图。非硬件位图是一种 JAVA 和 GPU 的内存优化,不是重点,简单说就是 Android 8.0的特性中提供的特性,之前 JAVA 侧的 Bitmap 需要在 GPU 侧同时也持有一份,现在在 JAVA 侧处理和之前一样,但是只是在GPU中占用内存。
复制到 RenderThread 中的除了 DisplayList ,还有 Damage Area(损坏区域)和 上传非硬件位图。非硬件位图是一种 JAVA 和 GPU 的内存优化,不是重点,简单说就是 Android 8.0的特性中提供的特性,之前 JAVA 侧的 Bitmap 需要在 GPU 侧同时也持有一份,现在在 JAVA 侧处理和之前一样,但是只是在GPU中占用内存。
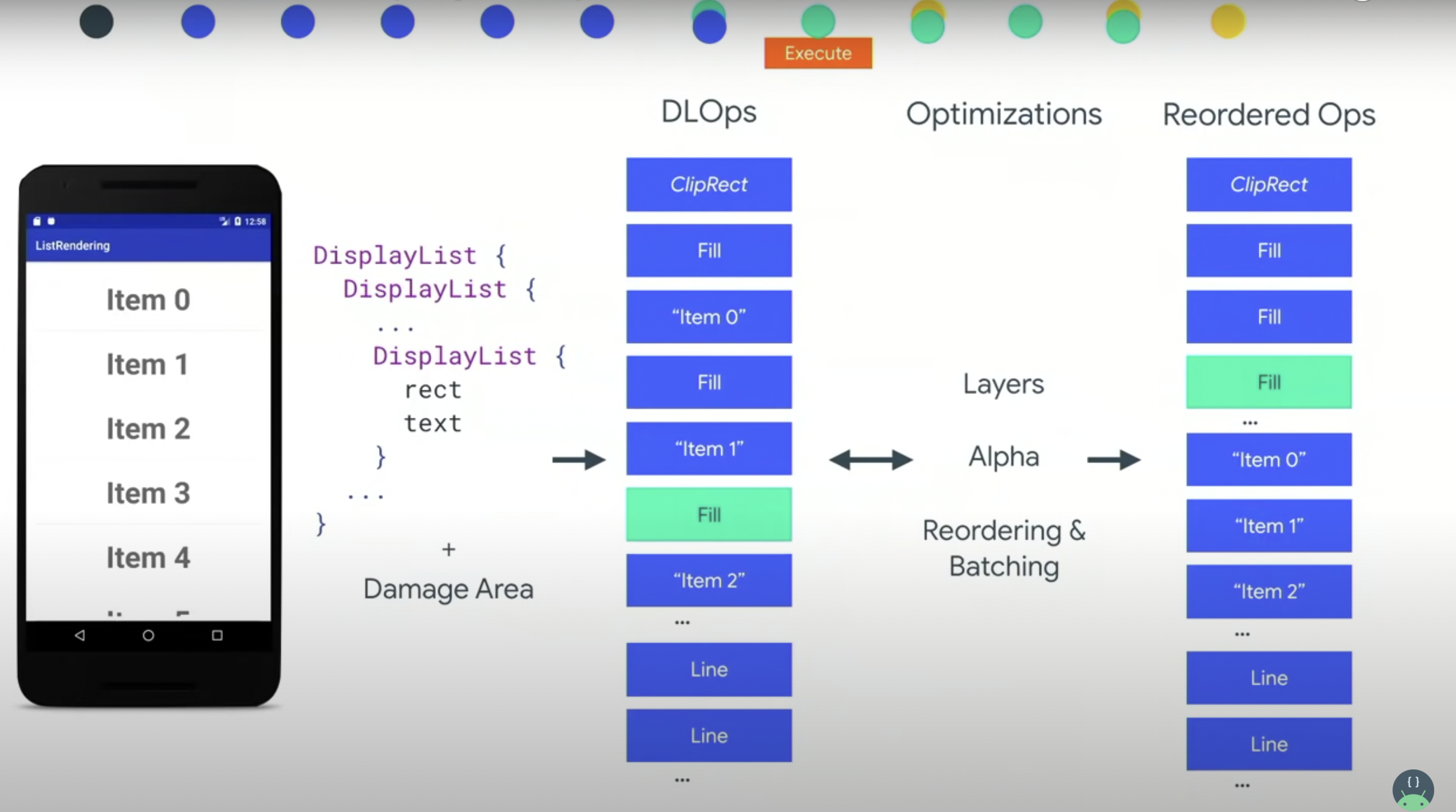 DLOps就是 DisplayList opratation(DisplayList的操作)。为了优化 GPU 的性能,降低切换成本,会重排序和匹配,这能显著降低性能消耗。重排序是针对种类,匹配是对图层。(针对图讲解一下)
DLOps就是 DisplayList opratation(DisplayList的操作)。为了优化 GPU 的性能,降低切换成本,会重排序和匹配,这能显著降低性能消耗。重排序是针对种类,匹配是对图层。(针对图讲解一下)
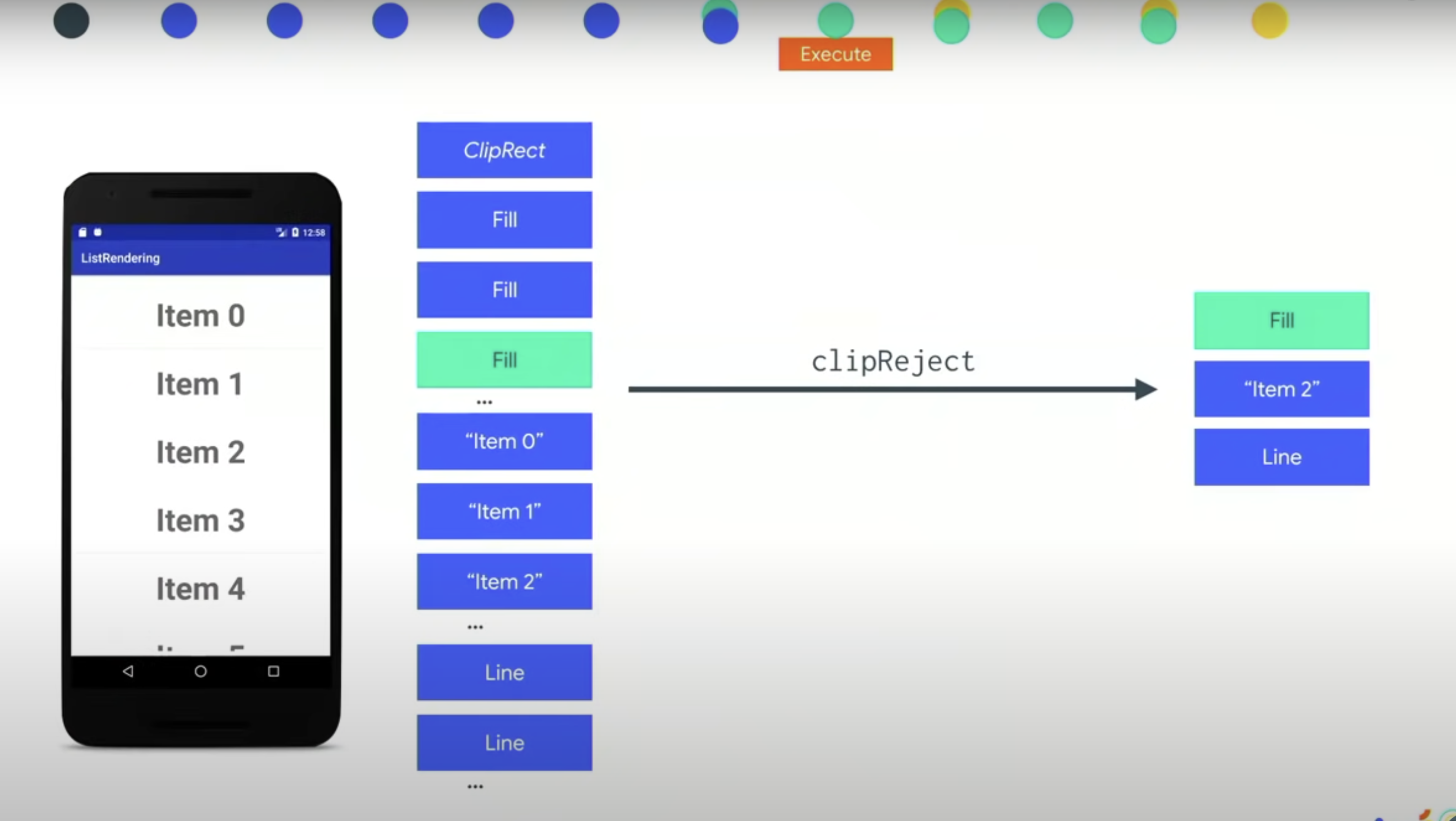 在处理 DLOps 时,结合 Damage Area 拒绝(Reject)掉所有不在这个区域的 DLOps ,所以最终我们只要做一个 Fill ,一个从字库缓存贴图里面的文本,一条线。
在处理 DLOps 时,结合 Damage Area 拒绝(Reject)掉所有不在这个区域的 DLOps ,所以最终我们只要做一个 Fill ,一个从字库缓存贴图里面的文本,一条线。
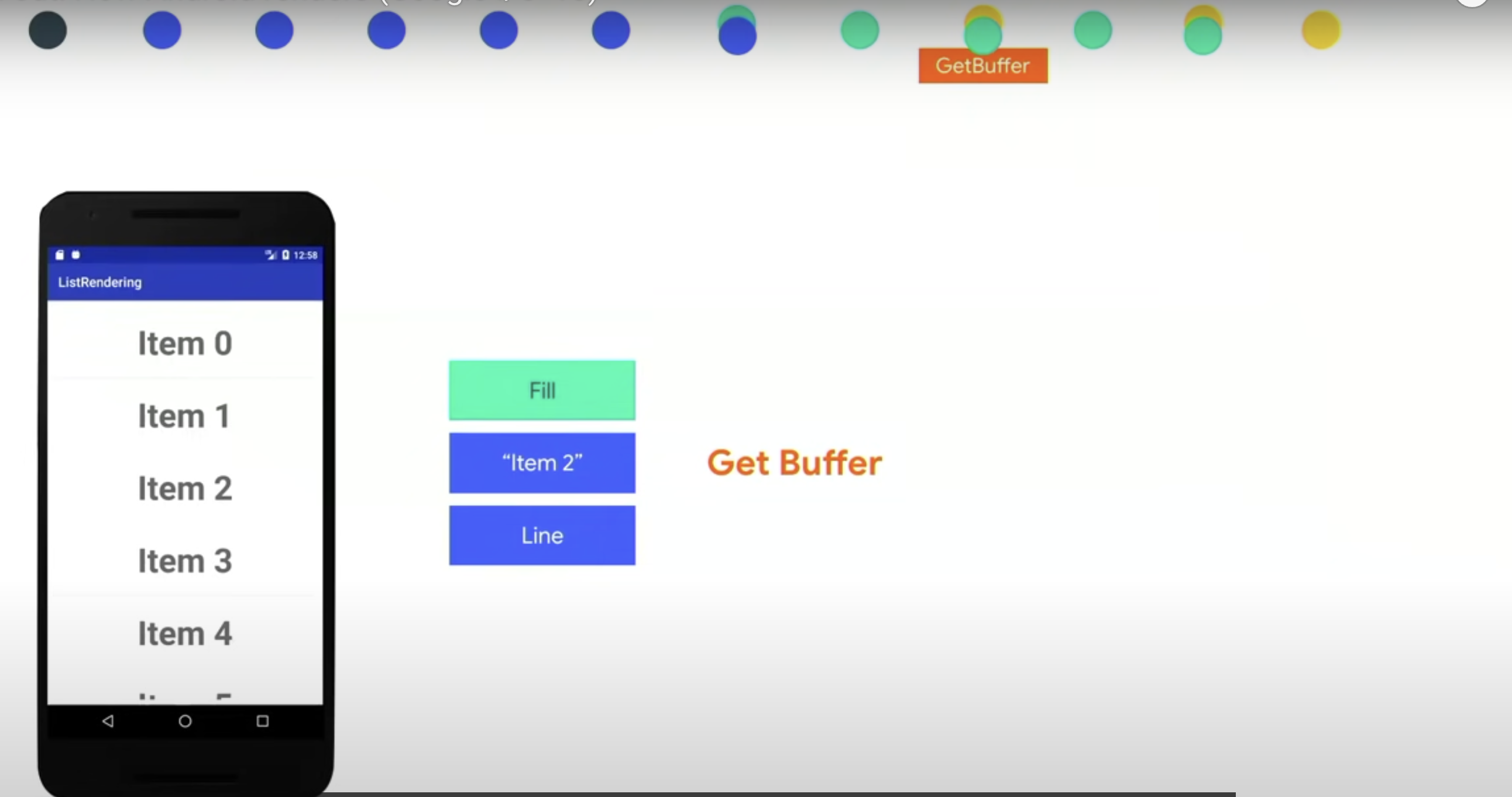 在我们操作 GPU 时,GPU 或者说 SurfaceFlinger 会将 Buffer 给到我们。
在我们操作 GPU 时,GPU 或者说 SurfaceFlinger 会将 Buffer 给到我们。
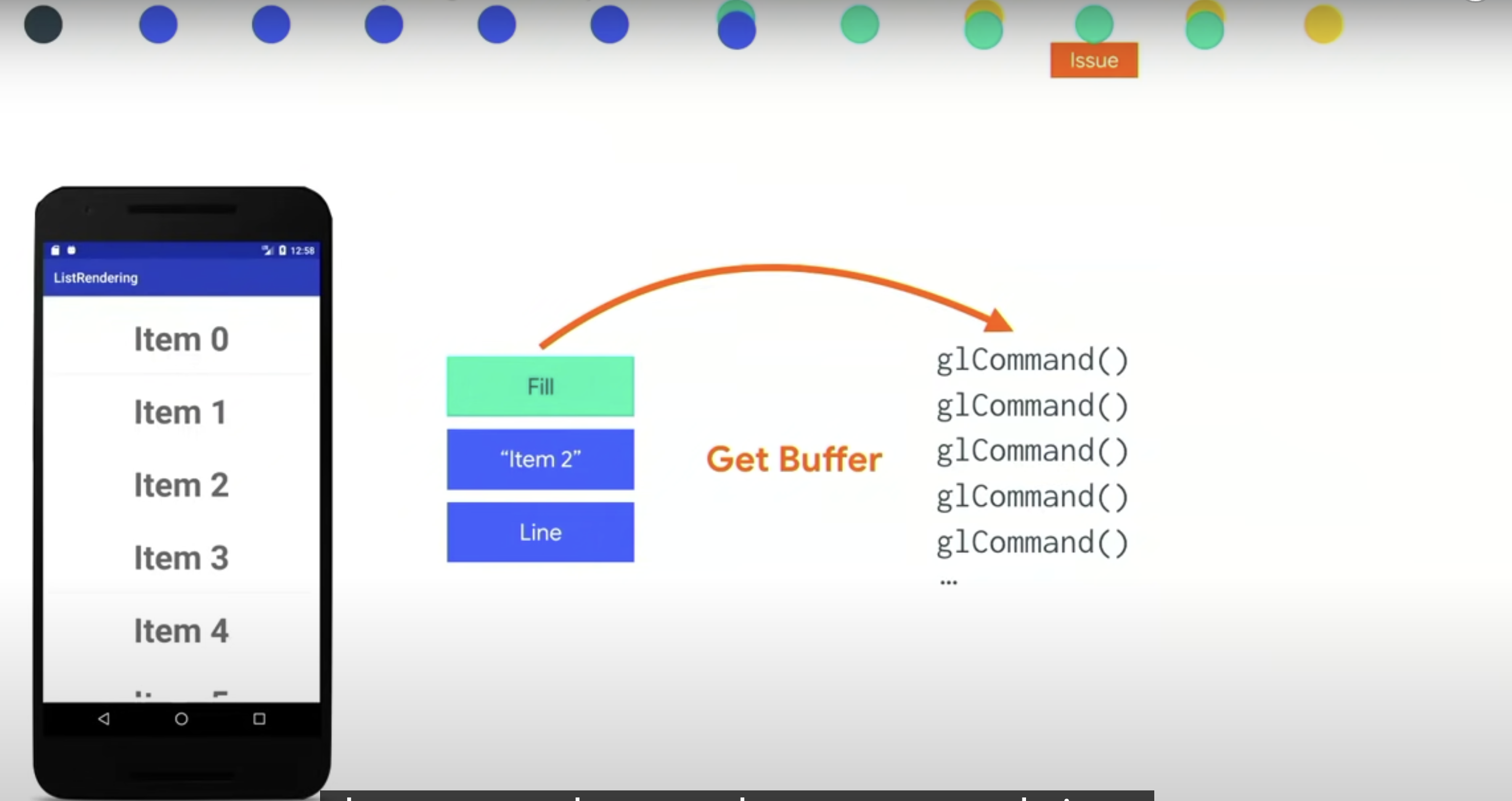 然后我们会 issue(发射) 一系列的 glCommand ,通常来说就是画线,文本,bitmap复制之类的 gl命令。
然后我们会 issue(发射) 一系列的 glCommand ,通常来说就是画线,文本,bitmap复制之类的 gl命令。
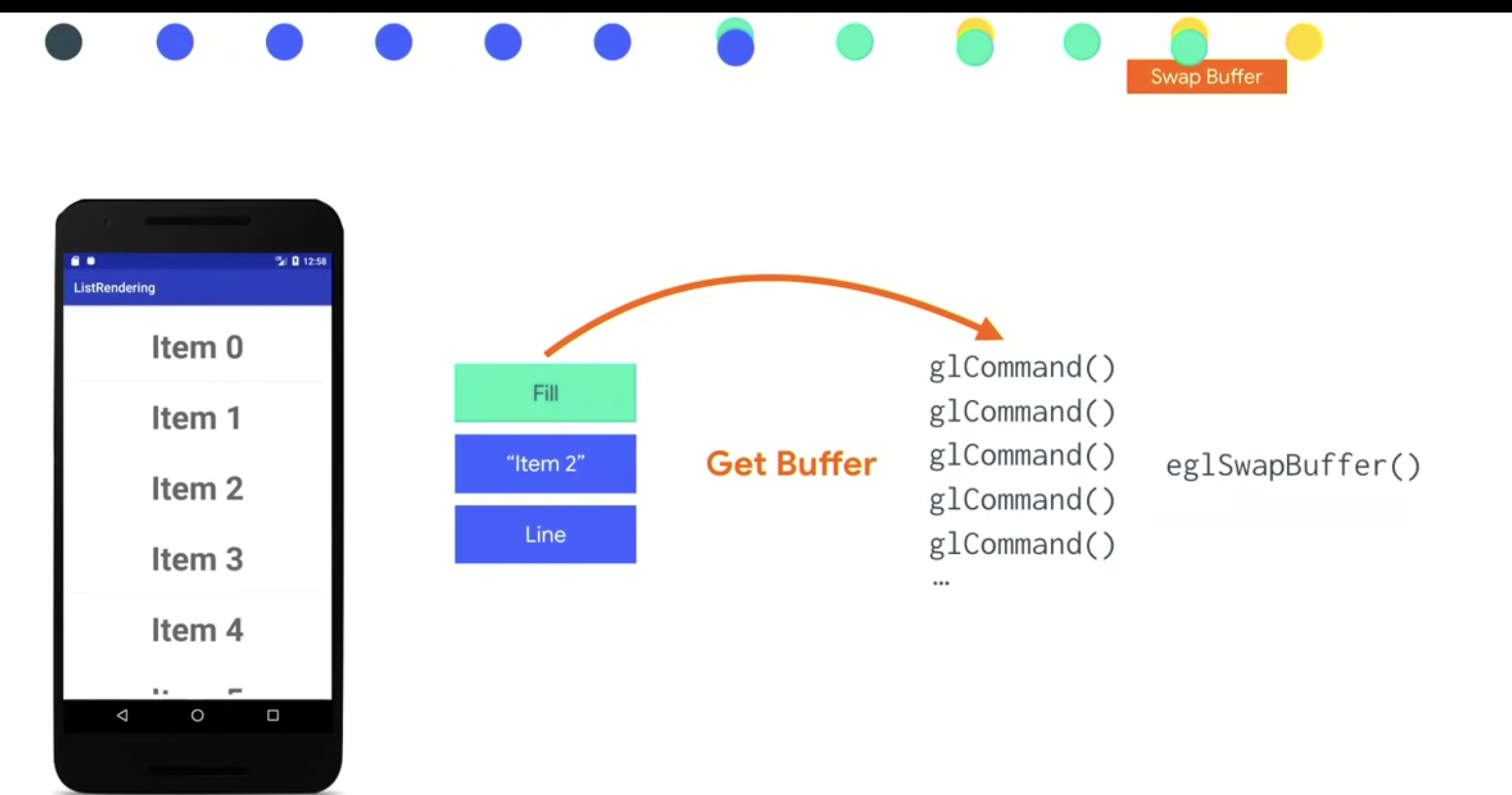 这一步,也就是所有的渲染操作已经完成,我们准备好将在屏幕上显示我们的这一帧,通过 SurfaceFlinger 的请求,和前台的 buffer 进行交换。
这一步,也就是所有的渲染操作已经完成,我们准备好将在屏幕上显示我们的这一帧,通过 SurfaceFlinger 的请求,和前台的 buffer 进行交换。
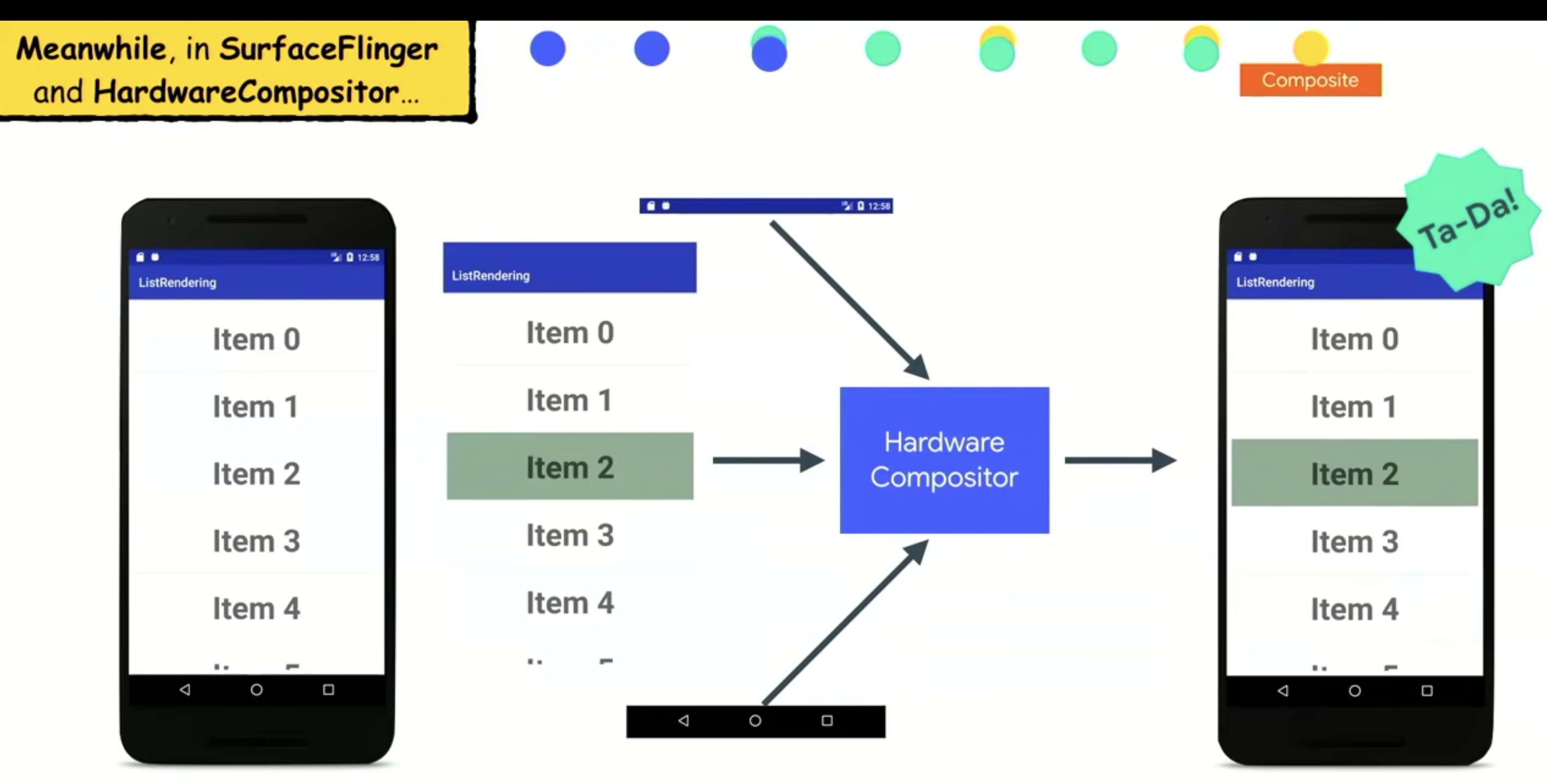 合成操作是和硬件打交到的最复杂的操作。这个时候屏幕上的所有的 window 都已经准备就绪,导航栏,状态栏,还有我们app页面,经过 HardwareCompositor(硬件合成器)最终合成。
合成操作是和硬件打交到的最复杂的操作。这个时候屏幕上的所有的 window 都已经准备就绪,导航栏,状态栏,还有我们app页面,经过 HardwareCompositor(硬件合成器)最终合成。
当一个用户向上拖动了 RecyclerView 的 item 发生了什么
 分两个阶段说,第一个阶段,只是移动。
分两个阶段说,第一个阶段,只是移动。
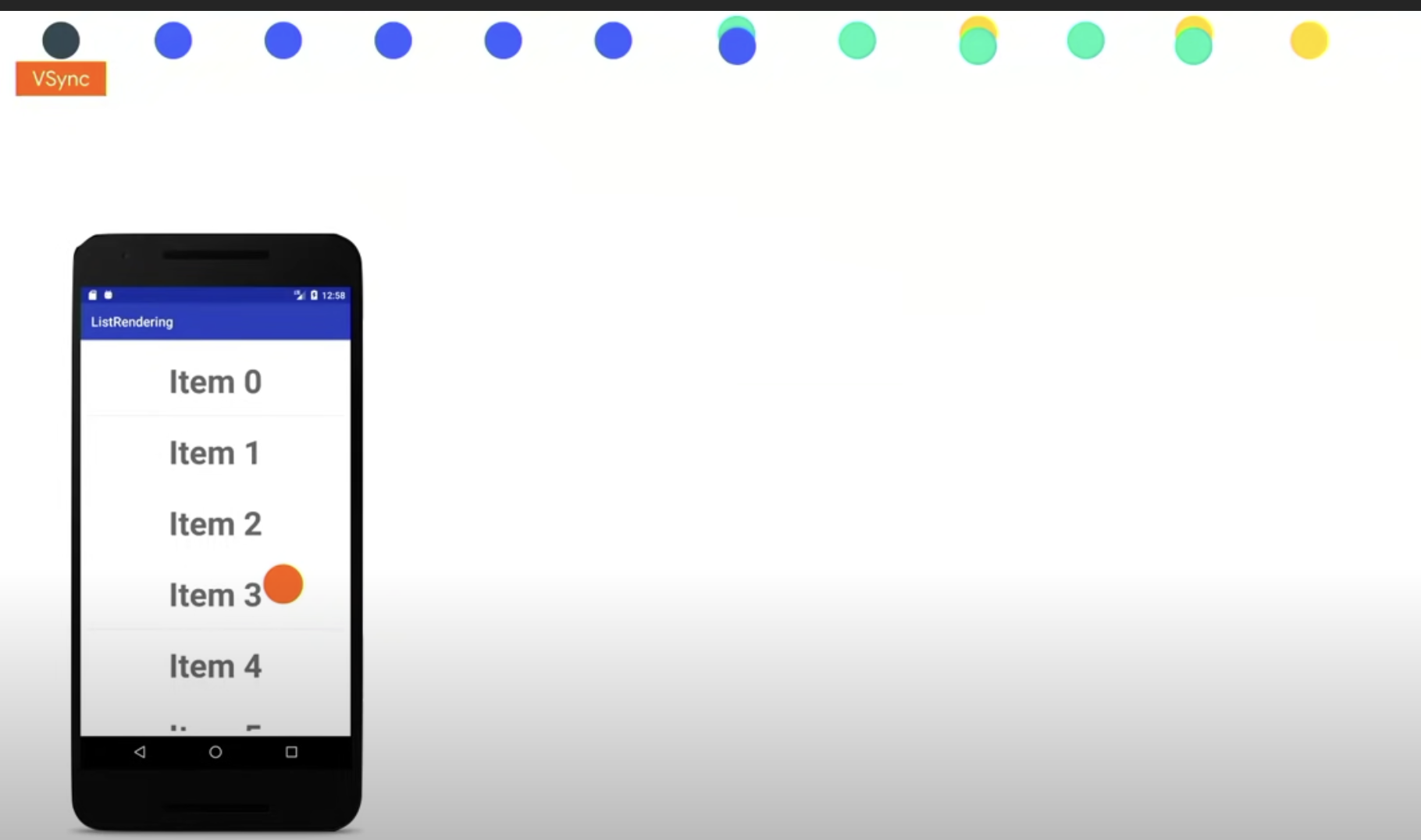 还是从 vSync 开始,和之前一样,准备处理一帧的数据。
还是从 vSync 开始,和之前一样,准备处理一帧的数据。
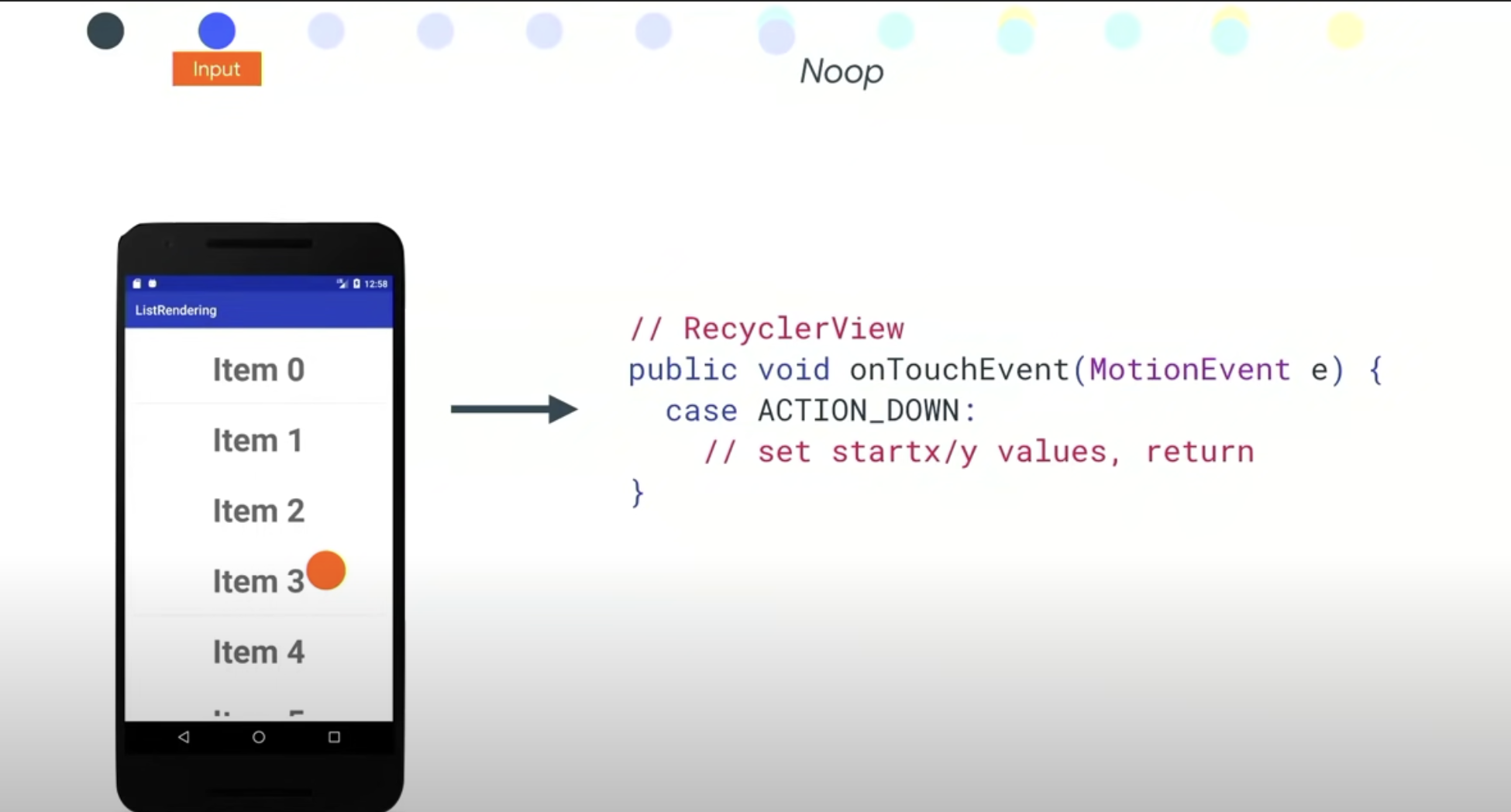 接收到了用户输入事件,按下动作,这个动作因为只是按下,所以并没有出发移动,也就没有任何其他事情发生。
接收到了用户输入事件,按下动作,这个动作因为只是按下,所以并没有出发移动,也就没有任何其他事情发生。
 用户拖动后,view 开始已经移动,这个时候,我们进行了 invalidate ,但是我们这里有个优化,因为只是 view 的移动,并没有 新view 被创建,所以我们调用了 invalidateViewProperty,这个方法会通过 DisplayList 的特性来做优化,通过只修改 View 对应的 DisplayList 的属性值,能非常快的被 GPU 所获取到。
用户拖动后,view 开始已经移动,这个时候,我们进行了 invalidate ,但是我们这里有个优化,因为只是 view 的移动,并没有 新view 被创建,所以我们调用了 invalidateViewProperty,这个方法会通过 DisplayList 的特性来做优化,通过只修改 View 对应的 DisplayList 的属性值,能非常快的被 GPU 所获取到。
 这个失效依然要被整个父类view所获取,来走 traversale
这个失效依然要被整个父类view所获取,来走 traversale
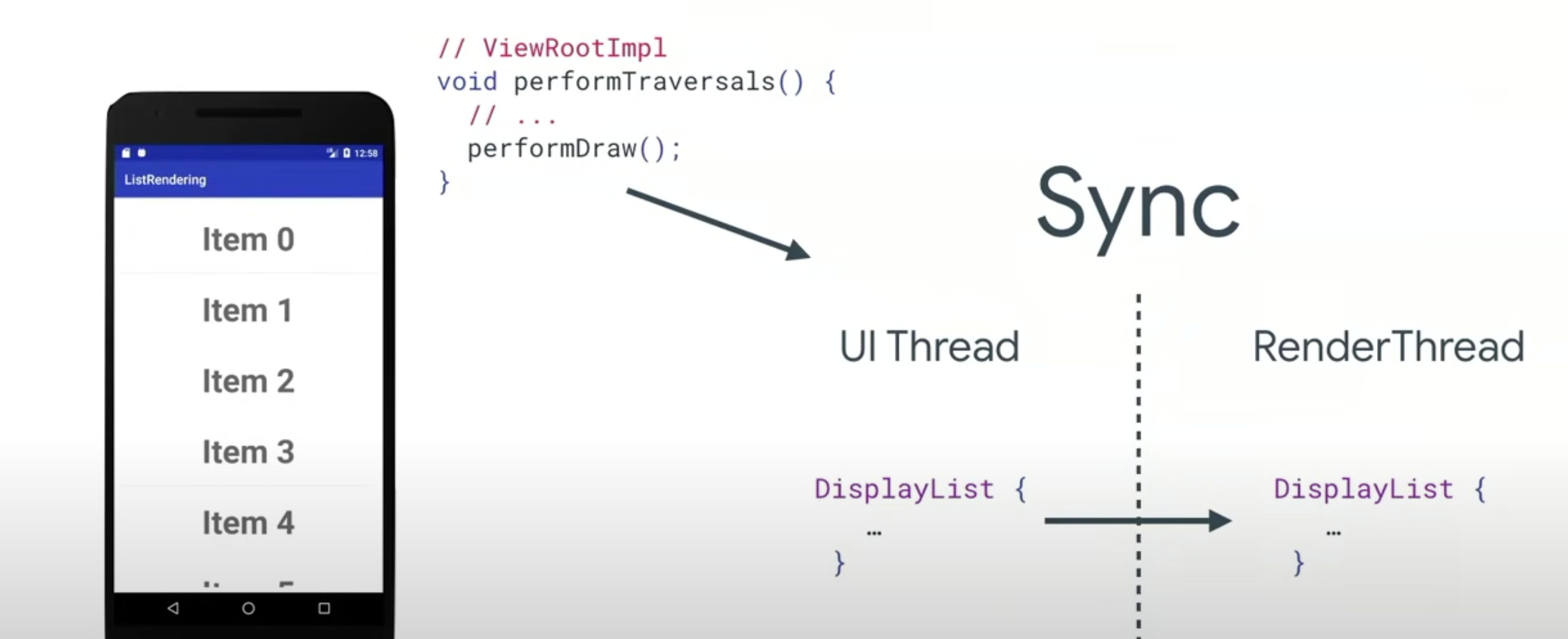 我们在 performDraw 里面有更简单的操作,因为 DisplayList 没有发生改变,只是某个属性发生了变化,所以我们可以立马进行 sync 给到渲染线程。
我们在 performDraw 里面有更简单的操作,因为 DisplayList 没有发生改变,只是某个属性发生了变化,所以我们可以立马进行 sync 给到渲染线程。



 之后和之前的一样。
之后和之前的一样。
 当拖动到一个新的 item 显示时。
当拖动到一个新的 item 显示时。
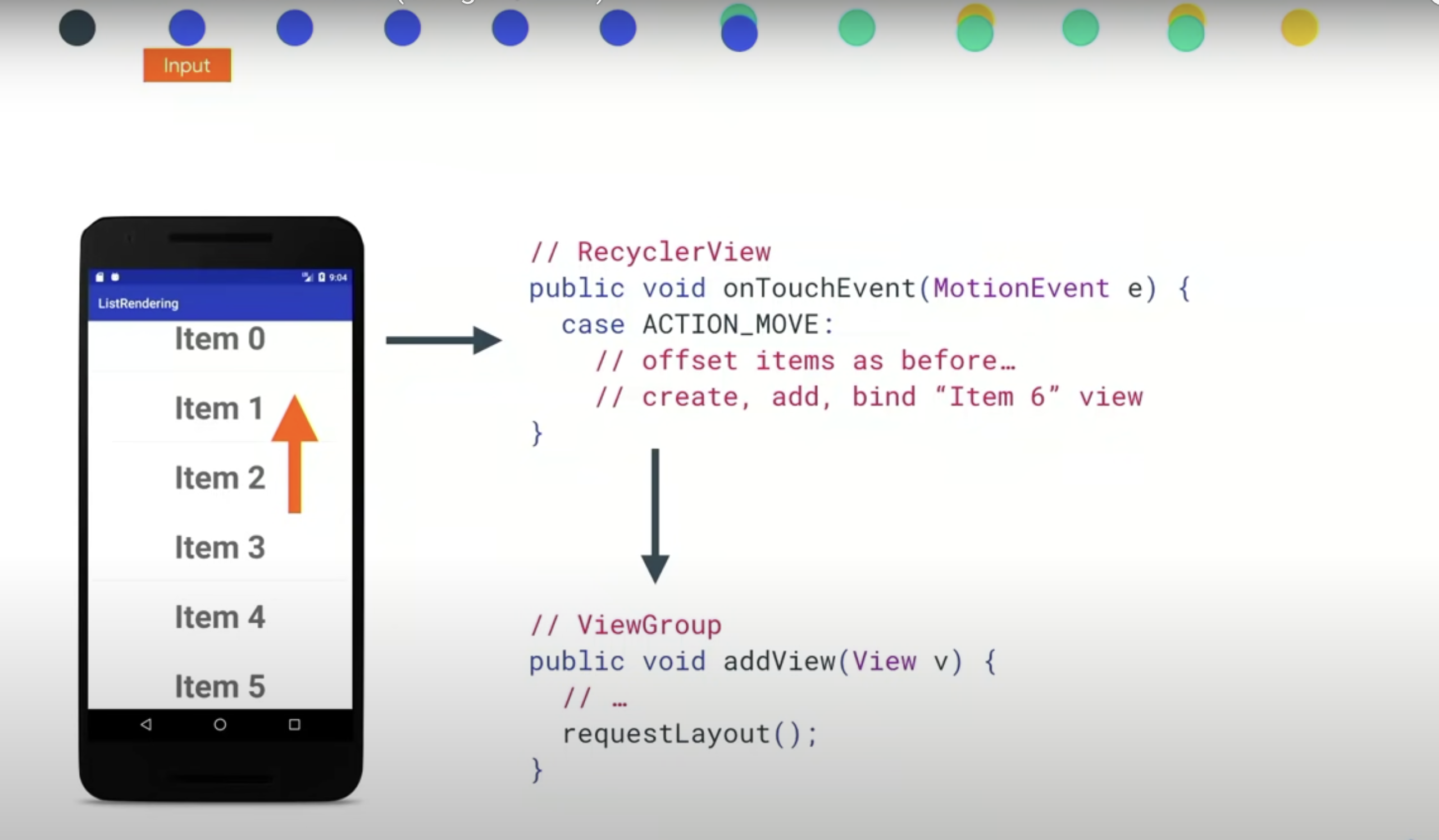 这个 move 里面不只是 offset了,我们会创建一个新的item。在viewGourp里面,addView时,会有一个 requestLayout 。
这个 move 里面不只是 offset了,我们会创建一个新的item。在viewGourp里面,addView时,会有一个 requestLayout 。
 有点像失效,但不是说要重新绘制, 而是需要被重新 maesure 和 layout。它也可能会导致页面其他的元素都需要变化,所以,这个流程也会从底部传递到顶部。
有点像失效,但不是说要重新绘制, 而是需要被重新 maesure 和 layout。它也可能会导致页面其他的元素都需要变化,所以,这个流程也会从底部传递到顶部。
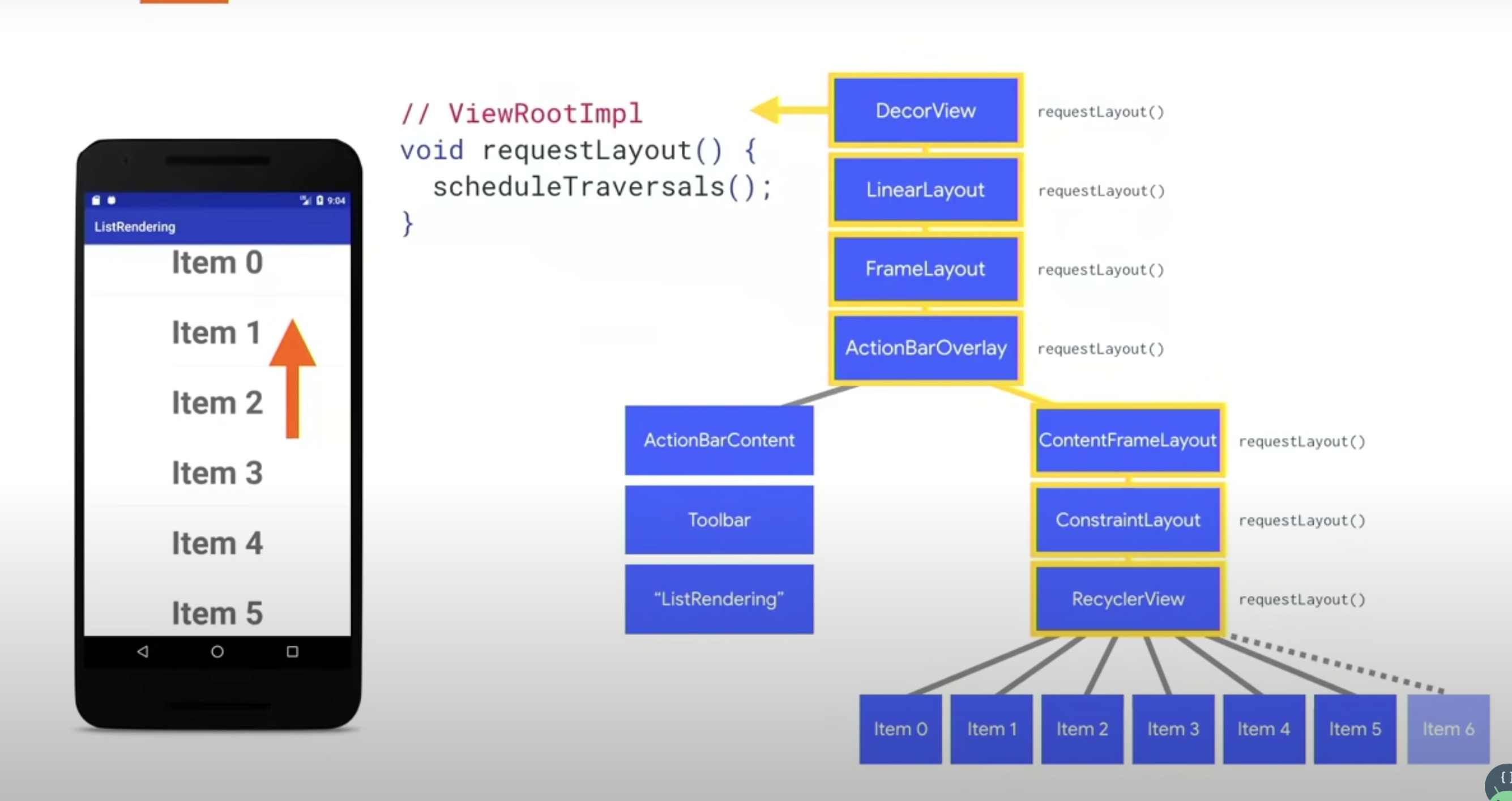 来到了我们的老盆友,scheduleTraversale这里。
来到了我们的老盆友,scheduleTraversale这里。
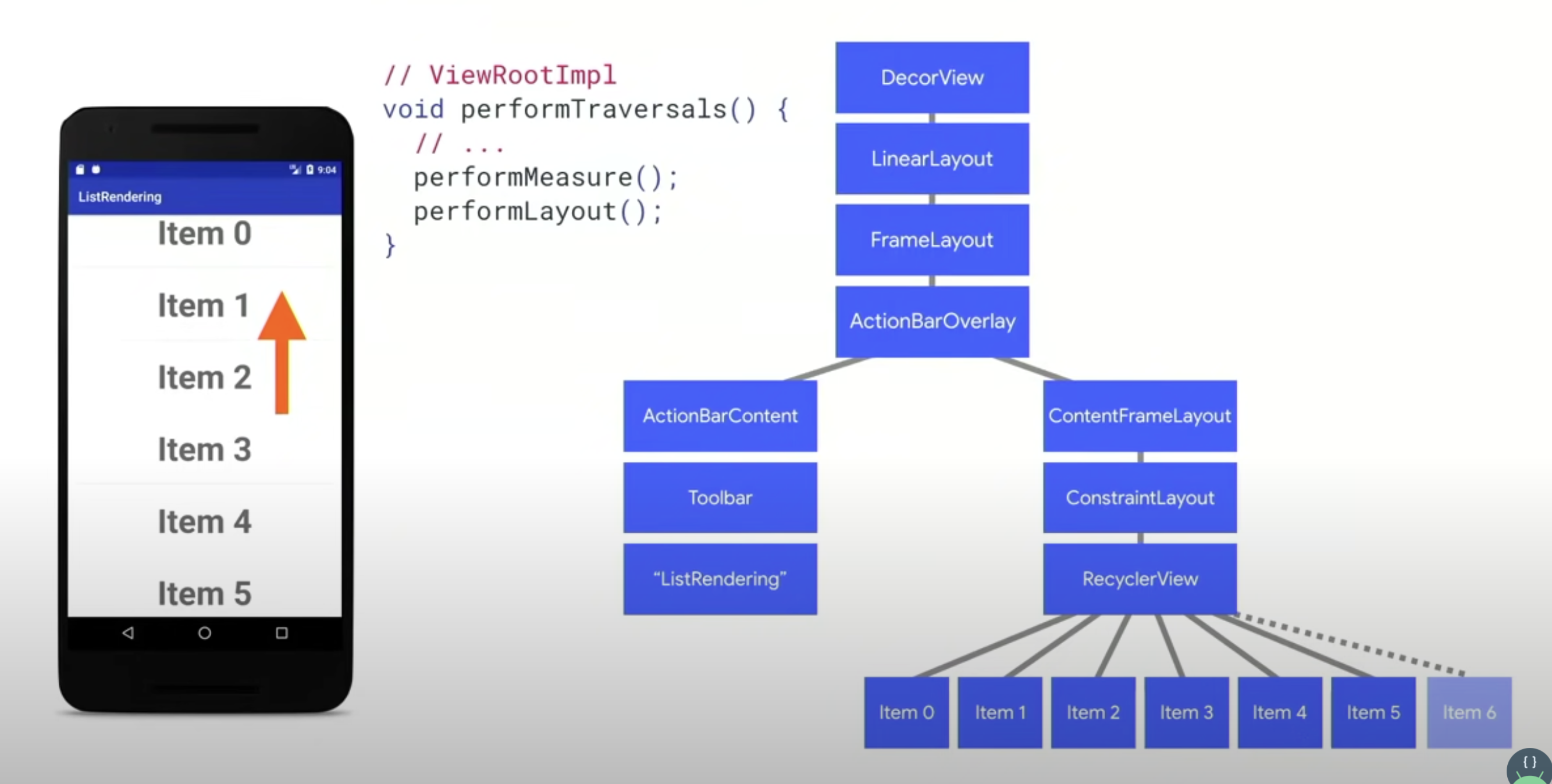 我们这次不讨论 draw,而来说说 performMeasure 和 performLayout
我们这次不讨论 draw,而来说说 performMeasure 和 performLayout
 在 android 中,maesure 是这个 view 请求的大小,比如fill_parent
在 android 中,maesure 是这个 view 请求的大小,比如fill_parent
 layout 就是告诉 view ,他们具体的大小和位置。
layout 就是告诉 view ,他们具体的大小和位置。
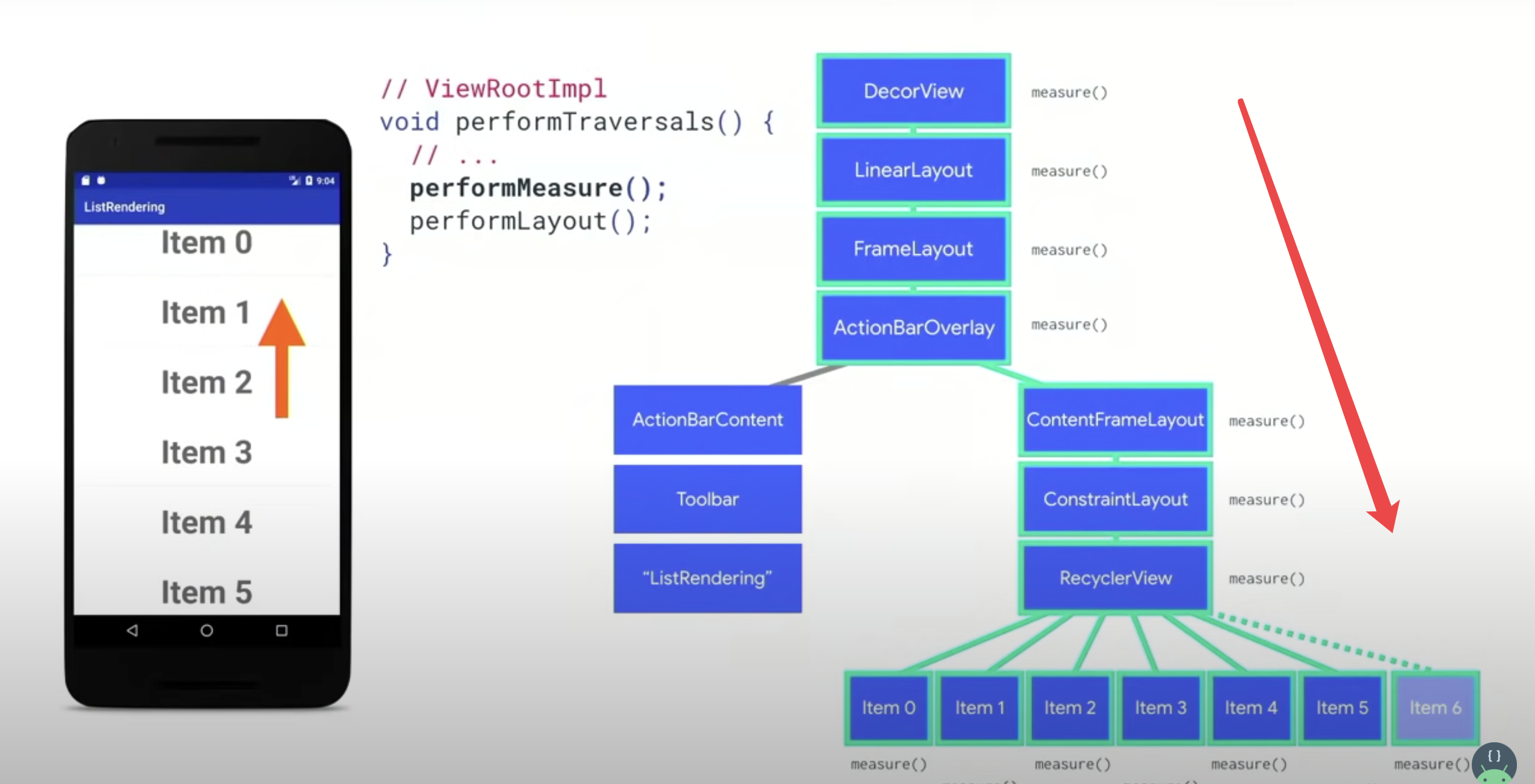 在performTraversales()里面调用performMeasure,它会从顶部开始往下一步一步调用来获得所有 view 想要的大小。这足以让我们计算布局。
在performTraversales()里面调用performMeasure,它会从顶部开始往下一步一步调用来获得所有 view 想要的大小。这足以让我们计算布局。
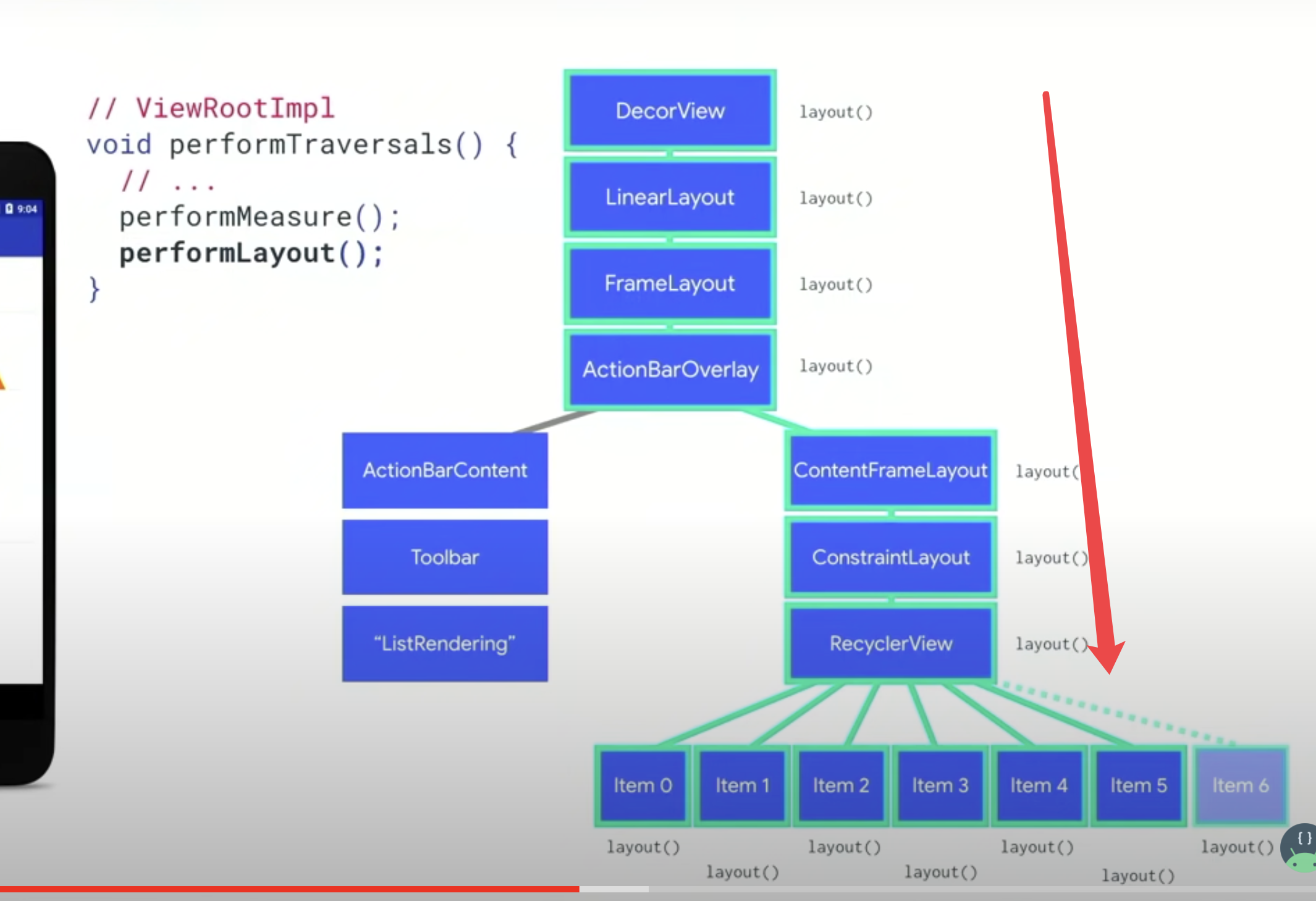 然后 layout 也是从顶部往下,根据刚刚获得的各个view需要的大小,决定具体该如何布局和定位。然后到了我们的 item6 根据以上信息被创建到对应的地点。
然后 layout 也是从顶部往下,根据刚刚获得的各个view需要的大小,决定具体该如何布局和定位。然后到了我们的 item6 根据以上信息被创建到对应的地点。
 剩下的和之前的draw一样,除了
剩下的和之前的draw一样,除了
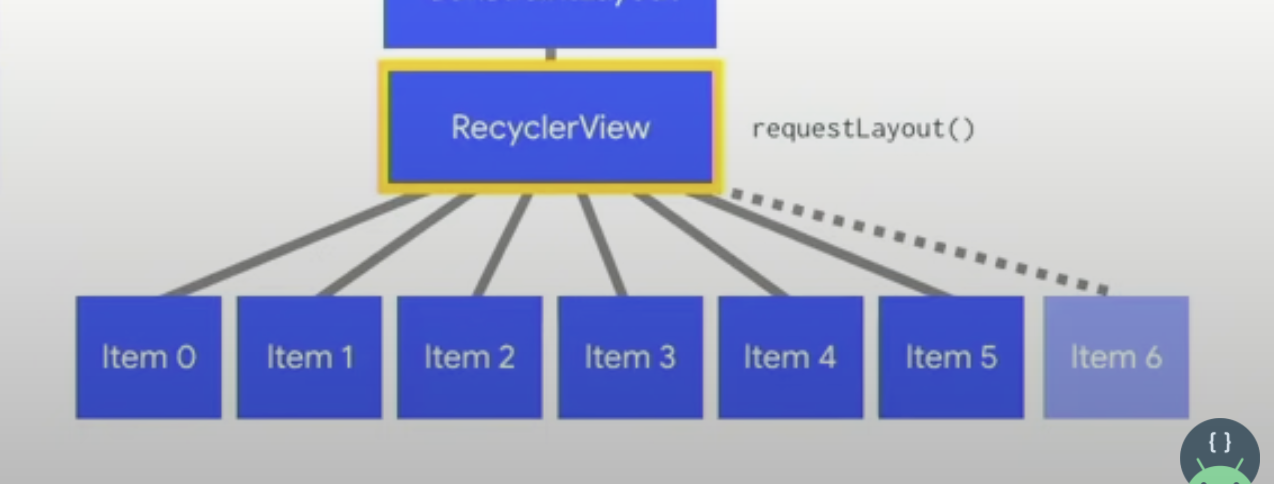 RecyclerView 其实本身做了优化,他对自己的父级和自级了解的足够多,不需要做刚刚从 requestLayout 的这套逻辑。所以他只需要做 offset View 并且 create item6 就行。
RecyclerView 其实本身做了优化,他对自己的父级和自级了解的足够多,不需要做刚刚从 requestLayout 的这套逻辑。所以他只需要做 offset View 并且 create item6 就行。
名词说明
VSync
在 Android 中,Vsync 需要做的事是:产生 Vsync 信号,通知 CPU/GPU 立即生成下一帧,通知 GPU 从 framebuffer 中将当前帧 post 到显示屏。即,生成帧时机必须和 Vsync 信号保持同步。 https://github.com/huanzhiyazi/articles/issues/28#ch2.2
Buffer
主要是避免CPU和GPU竞争资源,对用户来说也避免了画面撕裂。
双缓存技术中,Frame Buffer分为前帧缓存和后帧缓存,视频控制器永远只读取前帧缓存,GPU只控制后帧缓存的更新,在VSync信号发出的时候,前帧缓存和后帧缓存会瞬间切换(指针的交换)。这样当视频控制器在显示当前帧的时候,GPU可以同时渲染后一帧到后帧缓存中。 当CPU和GPU在16.7ms的时间内无法完成前面的工作,那么后帧缓存就无法提交,这一帧会被丢弃,视频控制器继续显示之前的一帧,从而产生卡顿。
Invalidation 无效化 api 说明
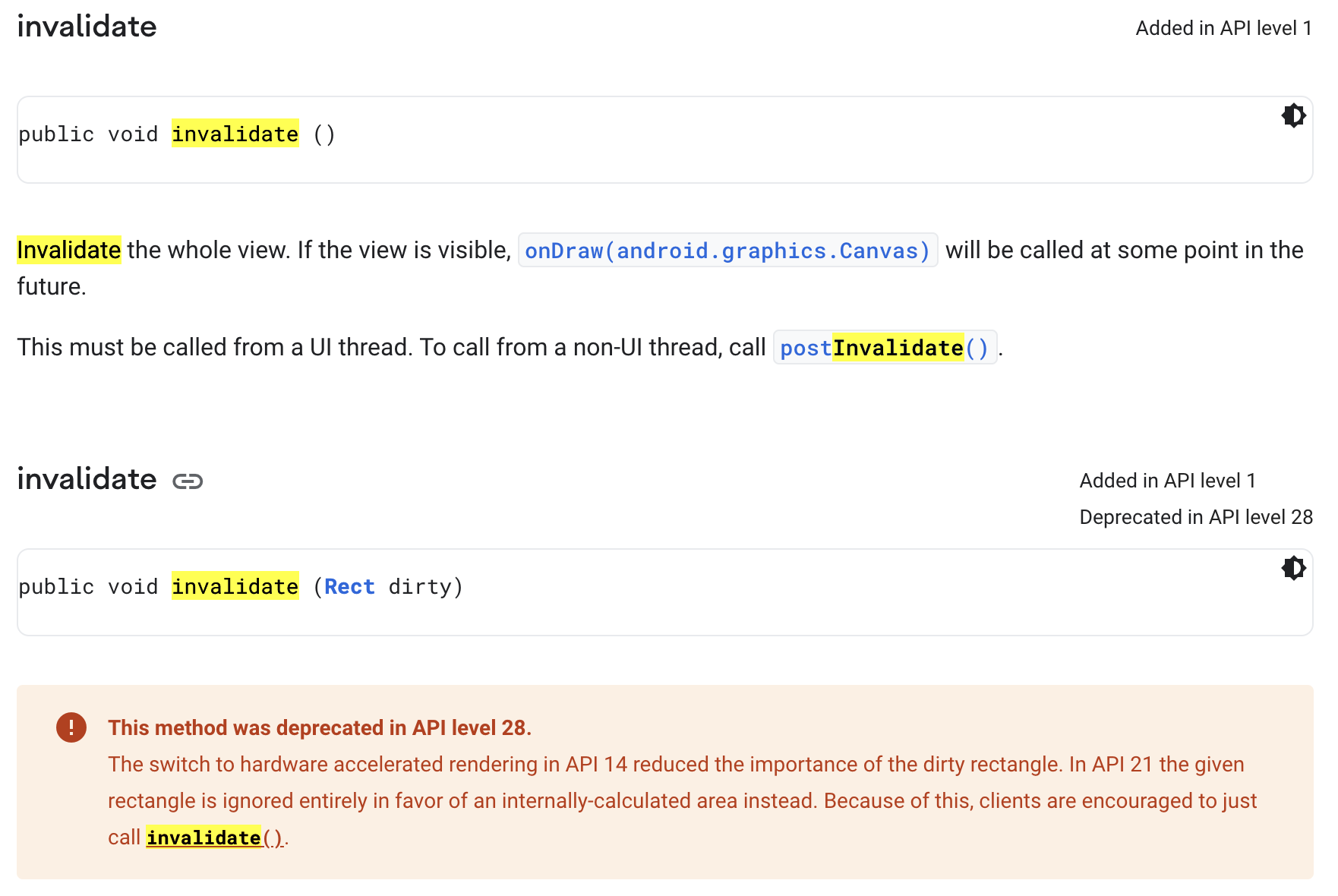 使整个视图无效。如果视图可见, onDraw(android.graphics.Canvas) 将在未来的某个时间点被调用。 这必须从 UI 线程调用。要从非 UI 线程调用,请调用 postInvalidate()。
下面的 invalidate(Rect dirty)的过期信息:
在 API 14 中切换到硬件加速渲染降低了脏矩形的重要性。在 API 21 中,给定的矩形被完全忽略,取而代之的是内部计算的区域。因此,鼓励客户只调用 invalidate()。
使整个视图无效。如果视图可见, onDraw(android.graphics.Canvas) 将在未来的某个时间点被调用。 这必须从 UI 线程调用。要从非 UI 线程调用,请调用 postInvalidate()。
下面的 invalidate(Rect dirty)的过期信息:
在 API 14 中切换到硬件加速渲染降低了脏矩形的重要性。在 API 21 中,给定的矩形被完全忽略,取而代之的是内部计算的区域。因此,鼓励客户只调用 invalidate()。
DisplayList



 https://blog.csdn.net/u011578734/article/details/110921300
https://blog.csdn.net/u011578734/article/details/110921300
Android的硬件加速
通常硬件加速就是指把某种特型计算工作交给的专门针对这部分计算而设计的硬件,比如把挖矿的运算给专门的挖矿的处理器,把游戏画面的渲染计算交给 GPU。在 Android 这里就是把 View 的绘制处理交给 GPU。换句话说,就是把 draw 到 canvas 上面的数据通过 GPU渲染管道 处理成像素点给屏幕。
https://developer.android.com/guide/topics/graphics/hardware-accel#controlling
DisplayList
 https://blog.csdn.net/u011578734/article/details/110921300
https://blog.csdn.net/u011578734/article/details/110921300
Android 绘制模型
其实分为两个部分,基于软件的绘制模型和硬件加速绘制模型。

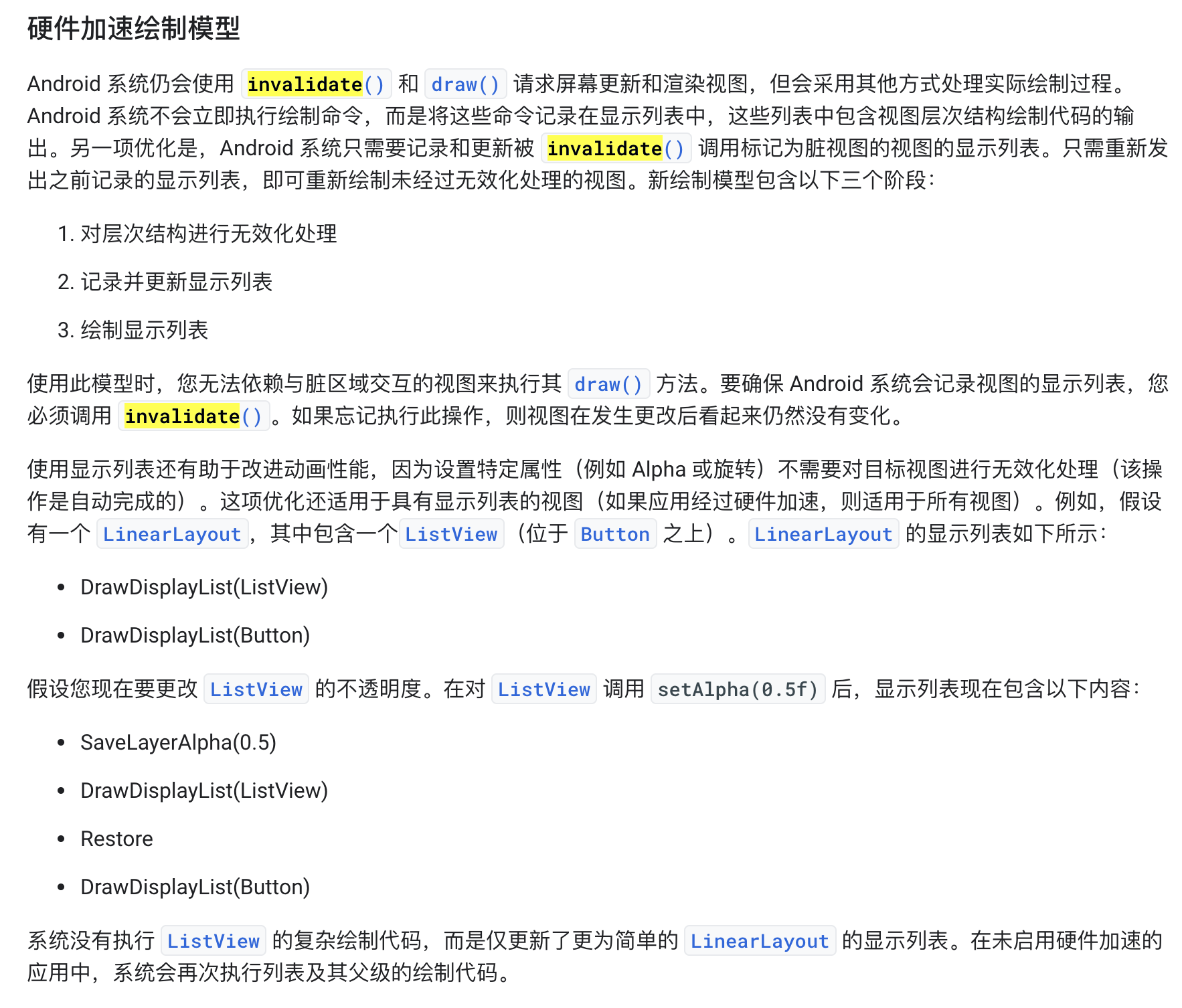 他们相同的部分都是会对调用 view 的无效化处理(invalidation)的层次结构进行一次遍历(Traversal)。不同的是软件绘制时,对 invalidate 的 view 计算了大小和位置,得到了一个 Rect ,也就是一块需要重新被绘制的脏区域,如果这个区域有多个 view 被叠加,那么他们在这个 rect 中的部分会被重新绘制;硬件绘制是会先把 DisplayList 更新新的 view ,然后通过 DisplayList 的整体结构进行合并(比如两个 view 的部分有重合,会避免重复绘制下面被盖住的部分;比如在视图外的 view 不会被渲染)。
他们相同的部分都是会对调用 view 的无效化处理(invalidation)的层次结构进行一次遍历(Traversal)。不同的是软件绘制时,对 invalidate 的 view 计算了大小和位置,得到了一个 Rect ,也就是一块需要重新被绘制的脏区域,如果这个区域有多个 view 被叠加,那么他们在这个 rect 中的部分会被重新绘制;硬件绘制是会先把 DisplayList 更新新的 view ,然后通过 DisplayList 的整体结构进行合并(比如两个 view 的部分有重合,会避免重复绘制下面被盖住的部分;比如在视图外的 view 不会被渲染)。
 https://blog.csdn.net/xiaosongluo/article/details/45070749
https://blog.csdn.net/xiaosongluo/article/details/45070749
| 渲染场景 | 纯软件绘制 | 硬件加速 | 加速效果分析 |
|---|---|---|---|
| 页面初始化 | 绘制所有View | 创建所有DisplayList | GPU分担了复杂计算任务 |
| 在一个复杂页面调用背景透明TextView的setText(),且调用后其尺寸位置不变 | 重绘脏区所有View | TextView及每一级父View重建DisplayList | 重叠的兄弟节点不需CPU重绘,GPU会自行处理 |
| TextView逐帧播放Alpha / Translation / Scale动画 | 每帧都要重绘脏区所有View | 除第一帧同场景2,之后每帧只更新TextView对应RenderNode的属性 | 刷新一帧性能极大提高,动画流畅度提高 |
| 修改TextView透明度 | 重绘脏区所有View | 直接调用RenderNode.setAlpha()更新 | 加速前需全页面遍历,并重绘很多View;加速后只触发DecorView.updateDisplayListIfDirty,不再往下遍历,CPU执行时间可忽略不计 |
https://tech.meituan.com/2017/01/19/hardware-accelerate.html
扩展
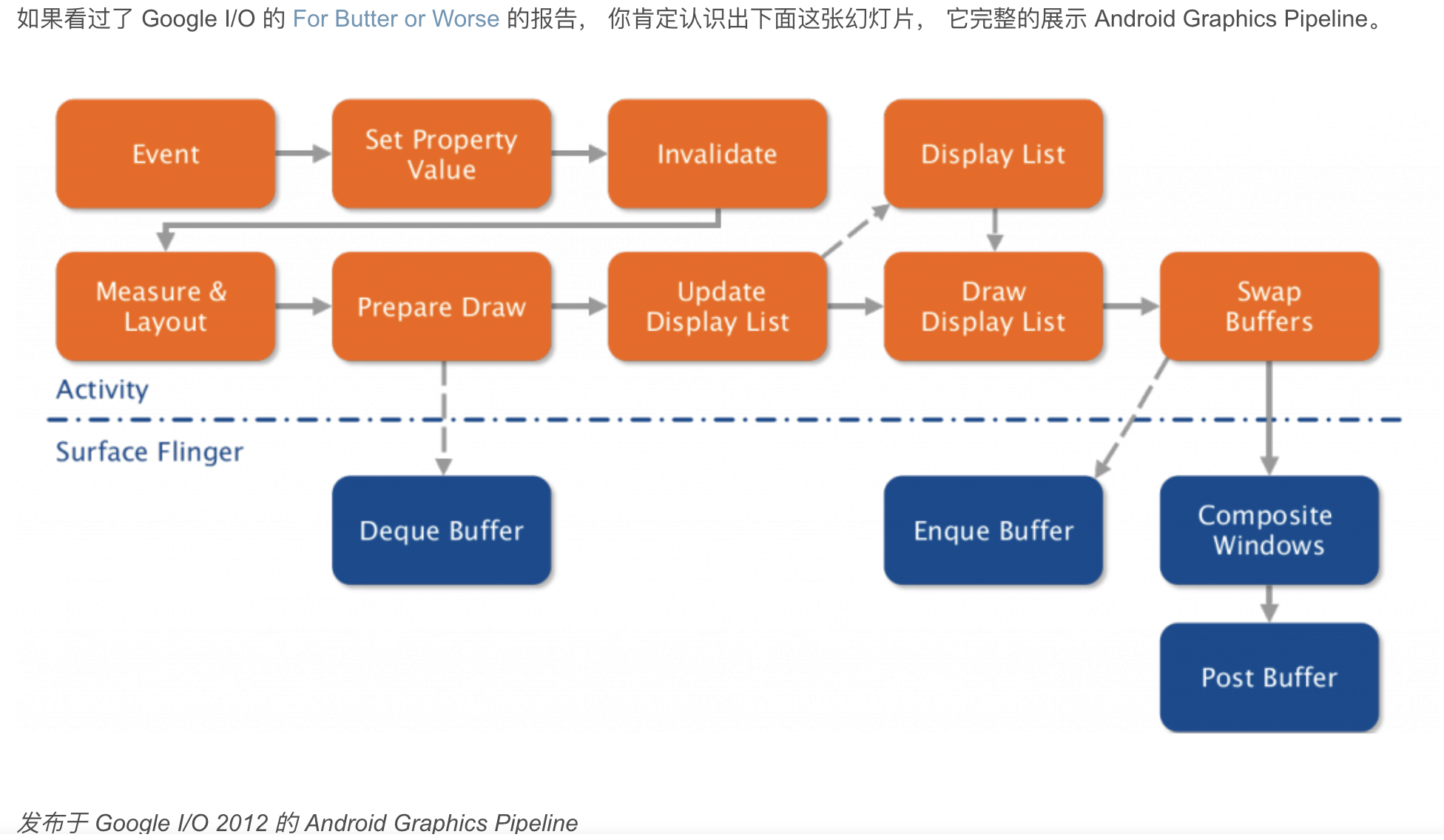 2012年的流程图。
2012年的流程图。
参考资料
- Drawn out: How Android renders (Google I/O ‘18) https://www.youtube.com/watch?v=zdQRIYOST64
- Android Graphics Pipeline :从Button到Framebuffer https://blog.csdn.net/xiaosongluo/article/details/45070749
- 图形架构 https://source.android.com/devices/graphics/architecture.html